
The power of small filters
: 두 3x3 (s=1) Conv layer를 쌓는다.
: 그럼, Second Conv Layer 한 개의 neuron은 input layer의 5x5를 보는 형태가 된다.

: 만약, 3x3 Conv layer를 3개를 쌓는다면? input layer의 7x7를 보는 것이다.
: Input-32x32x3, Filter-10 5x5, s=1, p=2일 때, parameter의 수는? (5x5x3+1)x10개 (+1은 bias)
7x7을 갖는 1개의 Conv Layer VS 3x3 3개 Conv Layer, (각 layer당 filter는 C개)
: 각각 weight의 수는? (7x7xC+1)xC, {(3x3xC+1)xC}x3
즉, 같은 영역을 보는건데, parameter의 수를 줄일 수 있음.
: 3번의 Conv Layer를 거치니까 nonlinearity를 강화!
당시 2016 강의에 있어서 SOTA가 해당 강의일에 ImageNet dataset기준 classification GoogLeNet이 SOTA
지금 SOTA 확인해보는데 정말 많은 모델이 생겼는게 체감이 확됐다.


Segmentation
: 우선, Segmentation에는 Semantic Segmentation, Instance Segmentation으로 나뉨
Semantic Segmentation
: 1 label per pixel (픽셀 단위로 label)
: Instance 각각을 구분하지는 못하고, classic computer vision에서는 classification 개수의 한계가 있고 이를 제외한 나머지는 background로 classificaiton
: Patch를 Extraction, 이를 기반으로 CNN을 수행함으로써 해당 patch를 classification
이 과정을 모든 Patch에 대해서 수행 (cost expensive)

Semantic Segmentation: Multi-Scale
: 여러 개의 scale이 다르게 resizing하고 각각 다른 CNN을 수행 후 upscaling하여 concat
: 추가적으로, 근접한 pixel을 기반으로 영역을 구분하는 방법(superpixels) 또는 Tree 방식으로 영역을 구분

Semantic Segmentation: Refinement
: R/G/B 분리하여 CNN을 적용하여 모든 label을 얻어내고, 다시 한 번 CNN 적용 ....반복
: 중요한 것은 여러 번의 CNN을 적용하는 동안 parameter weight sharing
: iteration이 많이질 수록 segmentation이 명확하게 됨

Semantic Segmentation: Upsampling
: Learnable upsampling (pixelwise prediction) layer 사용하여 image 복원
: 원본 이미지를 복원할 때, 초기일 수록 Feature map이 크지만, receptive field가 작으니까 원본 이미지를 복원할 때 세밀한 정보를 복원할 수 있지 않을까? 해서 skip connection 사용하고 Upsampling을 여러개 수행하여 Combine



Instance Segmentation
: Instance를 detect하고 각각의 instance내의 pixel을 label

: RNN과 비슷하게, proposals 방식으로 Instance를 detection
: Feature Extraction하여 Box CNN으로 Bbox를 추출하고,
Region CNN으로 background제거하여 이 둘을 concat하여 classification

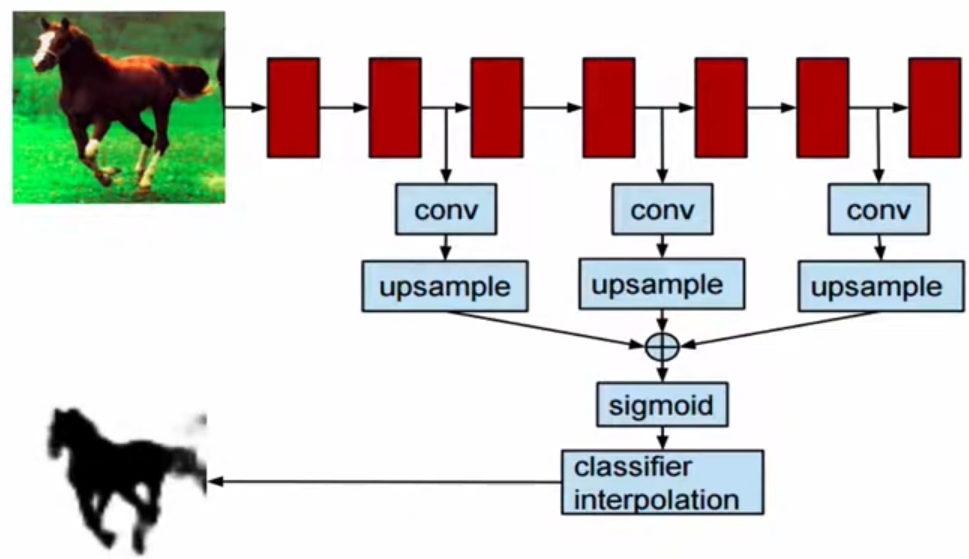
Instance Segmentation: Hypercolumns
: 앞서 언급한 Semantic Segmentation에서의 Multi-scale과 유사한 것 같다.
: 원본 image를 crop하고, crop한 image를 돌리면서, conv 과정에서 upsampling하고 concat하여서 region refinement
Instance Segmentation: Cascades
: ROI 영역을 추출하고, 이를 같은 size로 만들어서 Fully connected를 통해 mask instance를 추출
이를 다시 fully connected layer를 통해 instance를 predict


'Study > cs251n' 카테고리의 다른 글
| CS231n : lecture10_Recurrent Neural Networks, Image Captioning, LSTM (1) | 2024.12.09 |
|---|---|
| CS231n : lecture6,7_Training Neaural Networks (0) | 2024.12.09 |
| CS231n : lecture5_Convolutional Neural Networks (0) | 2024.12.07 |
| CS231n : lecture4_Introduction to Neural Networks (0) | 2024.12.04 |
| CS231n : lecture3_Loss Fn, Optimization (0) | 2024.12.04 |