
Convolution Neural Network Layer
Convolution Layer
: filter를 stride씩 옮겨가며 dot product 연산 + bias
: 해당 결과를 activation map이라고 부른다.

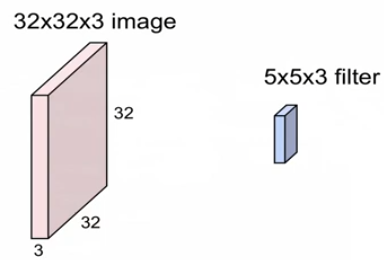
32x32x3을 conv layer를 거치고 28x28x6의 activation volumns를 가졌다면?
: 우선 채널이 6개이므로 kenel(filter)의 수는 6개.
: stride를 1(1칸씩 움직이며 계산)한다고 가정할 경우, 32를 몇의 크기 filter로 한 칸씩 움직이면 28일까?
: (N-F)/stride +1, (32-F)/1 +1 = 28, (32-F) = 27, F=5
(혹시, stride가 1보다 클 경우 넘어가는, 연산결과가 소수점이 나올텐데, 이럴 때는 padding추가)
: 즉, 5x5x3의 filter로 stride 1씩 해서 연산한게 된다. (이때, filter는 6개가 있다.)
: 추가적으로, filter가 weight이므로 weight는 총 5x5x3의 형태로 6개가 있는 것이다.
이러한 filter(weight)를 계속 학습하는 것이다.

: weight는 층을 더할 수록, high-level의 정보를 학습한다.


: depth가 동일한 activation map은 같은 weight를 공유하는 것이므로 sharing parameters
: depth가 다를 경우, 다른 weight(filter)에 의해 연산이 된 것이므로, non sharing parameters
: 하지만, depth는 다르지만, input의 같은 위치에 있으면 같은 곳을 바라보는 것이다.
Pooling Layer
크기를 줄여주는, downsampling해주는 Layer

: max pooling, min pooling, average pooling 등등
: weight가 없다는 것이 conv layer와의 차이, 학습을 하는게 아닌(weight가 없으므로) 단순히 down sampling 역할 수행
Fully Connected Layer (FC Layer)
: matrix mul해서 flattern 역할 -> 해당 score기반으로 softmax로 확률로 변경해서 최종 output을 내는 등
'Study > cs251n' 카테고리의 다른 글
| CS231n : lecture10_Recurrent Neural Networks, Image Captioning, LSTM (1) | 2024.12.09 |
|---|---|
| CS231n : lecture6,7_Training Neaural Networks (0) | 2024.12.09 |
| CS231n : lecture4_Introduction to Neural Networks (0) | 2024.12.04 |
| CS231n : lecture3_Loss Fn, Optimization (0) | 2024.12.04 |
| CS231n : lecture2_Image Classification pipline (1) | 2024.12.04 |