
(8,9에서는 visulization, 옛날 CNN paper를 통한 구조 설명이다. 이에 대해서는 SOTA paper review에서 진행하기에 skip)
RNN (Recurrent Neural Network)

: 일반적인 neural network는 첫 번째의 형태 (input layer -> hidden layer -> output layer)
: RNN에서는 input, output, hidden 등에 sequence를 추가하는 형태
: one to many - Image Captioning, Image를 Input하여 단어 Sequence를 output
: many to one - Sentiment Classification, 단어의 Sequence를 Input으로 하여 감정을 output
: many to many - Machine Translation, 단어의 Sequence를 Input하여 한국어 단어 Sequence Output
: many to many - Video classification, frame들을 받아서 시점을 기억하며 output 생성
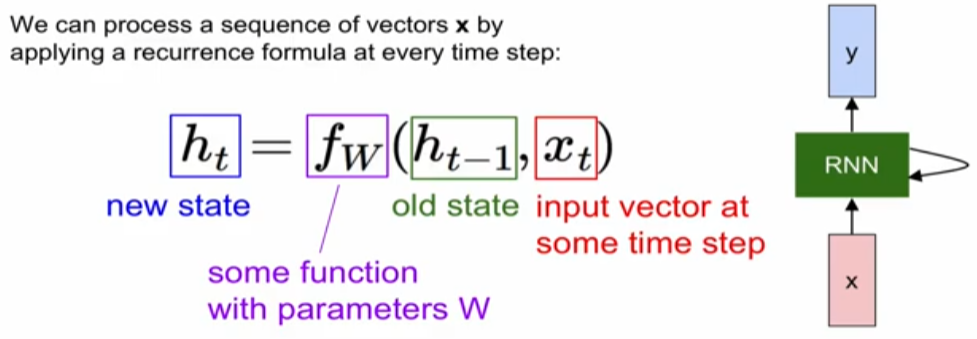
: 원하는 behavior를 갖도록 weight를 update
: 매 time step마다 동일한 parameter의 set을 가져야된다. (General하게 되려면)
Vanilla RNN
: state가 단일의 hidden vector h로만 구성
: 아래는 현재의 state는 직전의 state와 현재 input x_t로 표현
: x의 경우 x에서 hidden layer로 오는 weight의 영향을 받고, 현재의 state는 현재의 hidden layer와 직전의 hidden layer의 영향을 받는다. 즉, 과거와 현재의 입력값을 기반으로 h를 구성

Example(Character-level language model)
: 예제로 하나의 character가 들어왔을 떄, 다음 step에 나올 character를 예측하는 것을 구상
: one-hot-encoding이란 set of word(vocabulary)를 쉽게 대응되는 값으로 표현하는 것
: 앞에서 weight는 동일하다고 했다. 즉, input layer->hidden layer의 weight는 모두 같고, hidden layer-> output layer 또한 모두 같다.
: 만약 sequence가 매우 길다면, sequence length를 제한하면서 (chunk) input한다.

Image Captioning
: image를 받고 sequence of word를 output

CNN + RNN Image Captioning
: Convolution Layer를 통해 Image의 Feature Extraction
: 해당 Feature를 RNN의 Input을 하여 단어를 출력

LSTM
: RNN의 형태와 비슷하지만, hidden layer에 cell state가 추가
: cell state vector는 f(forget)을 통해 전 state를 어느정도 고려할 지를 결정하고, input을 cell state에 얼마나 g를 통해 더해줄 것인가를 결정
: 결론적으로, 현재의 cell state를 output에 반영함으로써 hidden state의 출력

'Study > cs251n' 카테고리의 다른 글
| CS231n : lecture11,13_CNNs in practice, Segmentaiton (0) | 2024.12.10 |
|---|---|
| CS231n : lecture6,7_Training Neaural Networks (0) | 2024.12.09 |
| CS231n : lecture5_Convolutional Neural Networks (0) | 2024.12.07 |
| CS231n : lecture4_Introduction to Neural Networks (0) | 2024.12.04 |
| CS231n : lecture3_Loss Fn, Optimization (0) | 2024.12.04 |