
Chapter 7에서는
* Time Series Resampling, 두 가지 유형의 Resampling과 이를 사용하는 주요 이유
* Pandas를 사용하여 Time Series Data를 더 높은 빈도로 Up Sampling하고 새로운 관측치를 Interpolation하는 방법
* Pandas를 사용하여 Time Series Data를 더 낮은 빈도로 Down Sampling하고 더 높은 빈도의 관측치를 요약하는 방법에 대해 배운다.
Resampling
* Two Types of resampling
1. Upsampling : 샘플의 빈도를 증가시키는 것 ex)빈도를 분 -> 초
2. Downsampling : 샘플의 빈도를 줄이는 것 ex)빈도를 일 -> 월
* Time Series Data를 resampling하는 데 관심이 있는 주된 이유
1. Problem Framing : 데이터를 예측하려는 주파수와 동일한 빈도로 하고자 할 경우 리샘플링이 필요할 수 있다.
2. Feature Engineering : Supervised learning models의 학습 문제에 대한 추가 구조 또는 통찰력을 제공하기 위해 리샘플링을 사용할 수 있다.
Shampoo Sales Dataset
* 이 Dataset은 3년 동안 월간 샴푸 판매 수에 대한 data이다.
* 일변량 데이터셋이며 36의 관측치가 있다.
* https://raw.githubusercontent.com/jbrownlee/Datasets/master/shampoo.csv
Upsampling Data
* 빈도를 매월에서 매일로 바꾸려면 업샘플링하고 보간 체계를 사용하여 새로운 일일 빈도를 채워야한다.
* Pandas library에서 series,dataframe object에 resample()이라는 함수를 제공한다.
* Upsampling할 때 새로운 공간을 만들 거나 Downsampling할 때 레코드를 그룹화할 때 사용한다.
* 시간을 문자열로 출력하기 위해 strptime()을 사용하고 아래의 예시에서는 '-'라는 구분자를 ,로 구분하며 시간을 나타낸다.
* parse_dates는 날짜를 datetime 형태로 변환할 지 여부이며 어떤 식으로 변환할지에 대한 것이 date_parser의 인자로 들어간다.
# upsample to daily intervals
from pandas import read_csv
from pandas import datetime
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, index_col=0, parse_dates=True,
squeeze=True, date_parser=parser)
upsampled = series.resample('D').mean()
print(upsampled.head(32))
Month
1901-01-01 266.0
1901-01-02 NaN
1901-01-03 NaN
1901-01-04 NaN
1901-01-05 NaN
1901-01-06 NaN
1901-01-07 NaN
1901-01-08 NaN
1901-01-09 NaN
1901-01-10 NaN
1901-01-11 NaN
1901-01-12 NaN
1901-01-13 NaN
1901-01-14 NaN
1901-01-15 NaN
1901-01-16 NaN
1901-01-17 NaN
1901-01-18 NaN
1901-01-19 NaN
1901-01-20 NaN
1901-01-21 NaN
1901-01-22 NaN
1901-01-23 NaN
1901-01-24 NaN
1901-01-25 NaN
1901-01-26 NaN
1901-01-27 NaN
1901-01-28 NaN
1901-01-29 NaN
1901-01-30 NaN
1901-01-31 NaN
1901-02-01 145.9
Freq: D, Name: Sales, dtype: float64* 위에서 NaN이라고 누락된 값을 보간할 수 있다. 이는 pandas에서 interpolate()라는 함수를 제공한다.
* 아래의 예시에서는 선형보간을 사용하고 이는 데이터 사이에 직선을 그려 그 직선을 토대로 data가 보간된다.
# upsample to daily intervals with linear interpolation
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, index_col=0, parse_dates=True,
squeeze=True, date_parser=parser)
upsampled = series.resample('D').mean()
interpolated = upsampled.interpolate(method='linear')
print(interpolated.head(32))
interpolated.plot()
pyplot.show()
Month
1901-01-01 266.000000
1901-01-02 262.125806
1901-01-03 258.251613
1901-01-04 254.377419
1901-01-05 250.503226
1901-01-06 246.629032
1901-01-07 242.754839
1901-01-08 238.880645
1901-01-09 235.006452
1901-01-10 231.132258
1901-01-11 227.258065
1901-01-12 223.383871
1901-01-13 219.509677
1901-01-14 215.635484
1901-01-15 211.761290
1901-01-16 207.887097
1901-01-17 204.012903
1901-01-18 200.138710
1901-01-19 196.264516
1901-01-20 192.390323
1901-01-21 188.516129
1901-01-22 184.641935
1901-01-23 180.767742
1901-01-24 176.893548
1901-01-25 173.019355
1901-01-26 169.145161
1901-01-27 165.270968
1901-01-28 161.396774
1901-01-29 157.522581
1901-01-30 153.648387
1901-01-31 149.774194
1901-02-01 145.900000
Freq: D, Name: Sales, dtype: float64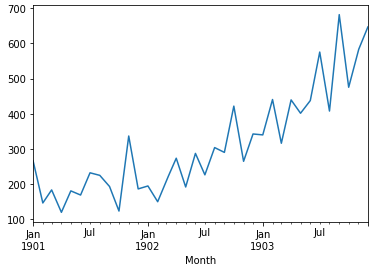
* 위에서 보간한 결과와 아래의 원시 dataset의 plot을 보면 차이가 거의 없을을 확인할 수 있다.
from pandas import read_csv
from matplotlib import pyplot
series = read_csv('shampoo-sales.csv', header=0, index_col=0,squeeze=True)
series.plot()
pyplot.show()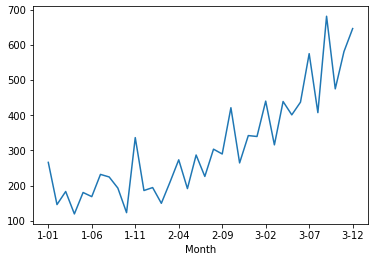
* 또 다른 일반적인 보간 방법에 다항식or스플라인을 사용하여 값을 연결하는 방법이 있다.
* 이렇게 하면 linear와 비교했을 때 더 많은 곡선이 생기므로 dataset을 더 자연스럽게 보간할 수 있다.
* 스플라인 보간을 사용하려면 다항식의 차수를 지정해야한다. (parameter 중 order가 이에 해당한다.)
* 스플라인 보간이란 곡선을 토대로 점을 잇는 보간법이다.
# upsample to daily intervals with spline interpolation
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, index_col=0, parse_dates=True,
squeeze=True, date_parser=parser)
upsampled = series.resample('D').mean()
interpolated = upsampled.interpolate(method='spline', order=2)
print(interpolated.head(32))
interpolated.plot()
pyplot.show()
Month
1901-01-01 266.000000
1901-01-02 258.630160
1901-01-03 251.560886
1901-01-04 244.720748
1901-01-05 238.109746
1901-01-06 231.727880
1901-01-07 225.575149
1901-01-08 219.651553
1901-01-09 213.957094
1901-01-10 208.491770
1901-01-11 203.255582
1901-01-12 198.248529
1901-01-13 193.470612
1901-01-14 188.921831
1901-01-15 184.602185
1901-01-16 180.511676
1901-01-17 176.650301
1901-01-18 173.018063
1901-01-19 169.614960
1901-01-20 166.440993
1901-01-21 163.496161
1901-01-22 160.780465
1901-01-23 158.293905
1901-01-24 156.036481
1901-01-25 154.008192
1901-01-26 152.209039
1901-01-27 150.639021
1901-01-28 149.298139
1901-01-29 148.186393
1901-01-30 147.303783
1901-01-31 146.650308
1901-02-01 145.900000
Freq: D, Name: Sales, dtype: float64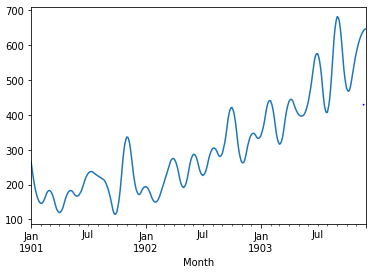
Downsampling Data
* 월별로 분리된 dataset이지만 분기 별 data를 선호할 수도 있다.
* resample()함수에서 parameter로 'Q'를 입력해주면 분기별로 분류할 수 있다.
* .3분기 (4개월씩)로 나누어지며 이를 mean()함수를 통해 분기별 평균을 계산한다.
# downsample to quarterly intervals
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, index_col=0, parse_dates=True,
squeeze=True, date_parser=parser)
resample = series.resample('Q')
#resample.plot()
#pyplot.show()
quarterly_mean_sales = resample.mean()
print(quarterly_mean_sales.head())
quarterly_mean_sales.plot()
pyplot.show()
Month
1901-03-31 198.333333
1901-06-30 156.033333
1901-09-30 216.366667
1901-12-31 215.100000
1902-03-31 184.633333
Freq: Q-DEC, Name: Sales, dtype: float64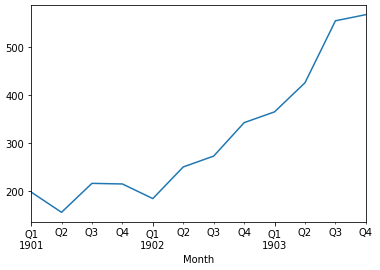
* 더 나아가 우리는 월별 데이터를 연간 데이터로 전환할 수 있다.
* 연말 빈도는 resample()함수에서 parameter로 'A'를 입력하면 연도별로 분류할 수 있다.
# downsample to yearly intervals
from pandas import read_csv
from pandas import datetime
from matplotlib import pyplot
def parser(x):
return datetime.strptime('190'+x, '%Y-%m')
series = read_csv('shampoo-sales.csv', header=0, index_col=0, parse_dates=True,
squeeze=True, date_parser=parser)
resample = series.resample('A')
yearly_mean_sales = resample.sum()
print(yearly_mean_sales.head())
yearly_mean_sales.plot()
pyplot.show()
Month
1901-12-31 2357.5
1902-12-31 3153.5
1903-12-31 5742.6
Freq: A-DEC, Name: Sales, dtype: float64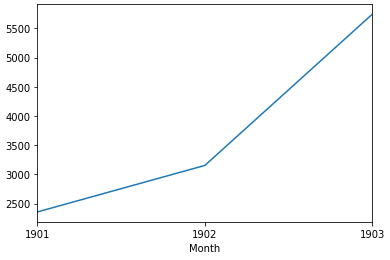
'Study > time series forecasting with python' 카테고리의 다른 글
| Chapter 8. Power Transforms (0) | 2021.07.12 |
|---|---|
| Chapter 7. 추가 내용 (0) | 2021.06.14 |
| Chapter 6. Data Visualization (0) | 2021.05.27 |
| Chapter 5. Basic Feature Engineering (0) | 2021.05.20 |
| Chapter 4. Load and Explore Time Series Data (0) | 2021.05.19 |