
Chapter 6에서는
* python을 사용하여 Time Series Data를 시각화 하는 데 사용할 수 있는 6가지 유형의 Plots
* line plots, lag plots, autocorrelation plots를 사용하여 structure of Time series를 탐색하는 방법
* box-whisker plots, heat map plots를 이용하여 구간에 따른 분포의 변화를 파악하는 방법에 대해 배운다.
Time Series Visualization
* Visualization은 Time Series analysis and forecasting에 중요한 역할을 한다.
* Plots of raw sample data는 model 선택에 영향을 미칠 수 있는 trend, cycles, seasonality와 같은 structure of time을 식별하는 귀중한 정보를 제공할 수 있다.
* Visualization에 사용되는 6가지 유형의 그림은 다음과 같다.
1. Line Plots
2. Histograms and Density Plots
3. Box and Whisker Plots
4. Heat Maps
5. Lag Plots or Scatter Plots
6. Autocorrelation Plots
* univariate time series에 초점을 둘거지만 variate time series에도 동일하게 적용하면 시각화 가능하다.
Minimum Daily Temperature Dataset
* 호주 멜버린시의 10년(1981-1990)에 걸친 일일 최저 온도에 대한 dataset이다.
* 날에 따른 온도 즉, time에 따른 하나의 변수(온도)에 대해 설명했기에 univariate time series dataset이다.
* https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-min-temperatures.csv

Line Plot
* Time Series를 Visualization하기 위해 가장 널리 쓰이는 방법이다.
* x축에 시간이 나타나며 y축에 그에 따른 관측치(일일 최저기온)에 대해 시각화한다.
# create a line plot
from pandas import read_csv
from matplotlib import pyplot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
series.plot()
pyplot.show()
* .plot()이라는 것에 parameter를 조정함으로써 그림의 형태를 바꿀 수 있다.
ex)
# create a dot plot
from pandas import read_csv
from matplotlib import pyplot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
series.plot(style='k.')
pyplot.show()
* 한 년도에 대하여 1-12월을 나누어서 line plots을 나타낼 수 있다.
* Grouper의 freq로 나누는 기준을 정할 수 있다. 이때 'A'는 year을 기준으로 나눈다는 것이다.
* grouby의 return은 dataframe [0]에는 year, [1]에는 min temperature data가 저장된다.
# create stacked line plots
from pandas import read_csv
from pandas import DataFrame
from pandas import Grouper
from matplotlib import pyplot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
groups = series.groupby(Grouper(freq='A'))
years = DataFrame()
for name, group in groups:
years[name.year] = group.values
years.plot(subplots=True, legend=False)
pyplot.show()
Histogram and Density Plots
* histogram을 사용하면 각 구간에 속하는 관측치가 몇 개씩 있는 지 알 수 있다.
# create a histogram plot
from pandas import read_csv
from matplotlib import pyplot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
series.hist()
pyplot.show()
* Density plot을 통해 전체적인 분포의 모양을 알 수 있다.
* 히스토그램을 선으로 나타낸 것이라고 볼 수 있다.
* 아래의 코드를 통해 우리는 가우시안분포라기에는 비대칭적이고 다소 뾰족하다는 것을 알 수있다.
* kde는 kernel density estimation의 줄임말로 PDF를 추정하는 방법
# create a density plot
from pandas import read_csv
from matplotlib import pyplot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
series.plot(kind='kde')
pyplot.show()
Box and Whisker Plots by Interval
* histogram과 density plot은 모든 관측치의 분포에 대해 나타내는 것이지만 시간 간격에 의한 값 분포에는 상관이 없다.
* 시간 간격에 따른 분포를 알기 위해 Box and Whisker Plots을 활용할 수 있다.
* 이전에 groupby, Grouper를 이용하여 년도별 data를 나누고 년도별 box whisker plots을 그리는 예제이다.
# create a boxplot of yearly data
from pandas import read_csv
from pandas import DataFrame
from pandas import Grouper
from matplotlib import pyplot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
groups = series.groupby(Grouper(freq='A'))
years = DataFrame()
for name, group in groups:
years[name.year] = group.values
years.boxplot()
pyplot.show()

* 우리는 년도별이 아닌 한 년도에 대해 각 월에 대한 data도 보고 싶을 수 있다.
* 아래의 예제에서는 1990년도 1-12월달에 대한 box and whisker plot을 그린다.
* raw에는 1-31일에 대한 min temperature data들을 dataframe형식으로 저장하고 column 이름을 1-12로 지정해준다.
# create a boxplot of monthly data
from pandas import read_csv
from pandas import DataFrame
from pandas import Grouper
from matplotlib import pyplot
from pandas import concat
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
one_year = series['1990']
groups = one_year.groupby(Grouper(freq='M'))
months = concat([DataFrame(x[1].values) for x in groups], axis=1)
months = DataFrame(months)
months.columns = range(1,13)
months.boxplot()
pyplot.show()

Heat Maps
* 큰 값은 따뜻한 색(노란색 및 빨간색), 작은 값은 차가운 색(파란색 및 녹색)으로 그림을 그린다.
* 아래 예제를 통해 1-12월 중 6-10월이 최저기온을 가진 것을 확인할 수 있다.
* .T(전치)를 통해 x,y를 변경할 수 있다.
* matshow를 통해 heat maps을 표현하며 parameters years는 data, interpolation은 보간법, aspect는 종횡비이다.
* 보간법에 따른 표현법 종류

# create a heat map of yearly data
from pandas import read_csv
from pandas import DataFrame
from pandas import Grouper
from matplotlib import pyplot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
groups = series.groupby(Grouper(freq='A'))
years = DataFrame()
for name, group in groups:
years[name.year] = group.values
years = years.T
pyplot.matshow(years, interpolation=None, aspect='auto')
pyplot.show()
* 이를 변형하여 1년 내의 1-12월을 비교할 수 있다.
# create a heat map of monthly data
from pandas import read_csv
from pandas import DataFrame
from pandas import Grouper
from matplotlib import pyplot
from pandas import concat
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
one_year = series['1990']
groups = one_year.groupby(Grouper(freq='M'))
months = concat([DataFrame(x[1].values) for x in groups], axis=1)
months = DataFrame(months)
months.columns = range(1,13)
pyplot.matshow(months, interpolation=None, aspect='auto')
pyplot.show()
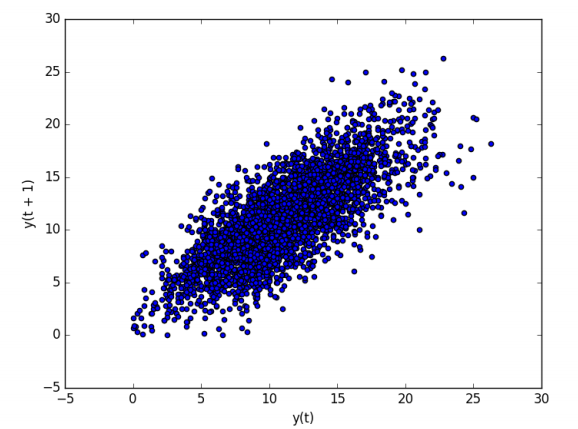
Lag Scatter Plots
* Time Series의 이전 관측치를 'lag'라고 하며 이전 시간 단계 관측치는 lag=1, 두 시간 전 관측치를 lag=2로 표현한다.
* 각 관측치와 해당 관측치의 지연 사이의 관계를 조사하는 유용한 유형이 산점도이다.
* 이 그래프틑 x축에 시간 t의 관측치, y축에 다음 시간 단계 (t+1)의 관측치를 표시한다.
* 이 그래프는 좌하단에서 우상단으로 향하며 이를 양의 상관관계라고 부른다.
# create a scatter plot
from pandas import read_csv
from matplotlib import pyplot
from pandas.plotting import lag_plot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
lag_plot(series)
pyplot.show()
* 여러 지연에 따른 산점도를 그리는 예시이다.
* lag=1부터 lag=7까지의 산점도를 그리며, shift를 통해 지연을 나타내며 이를 concat으로 column결합한다.
* 또한 그림을 그릴 때는 서브플롯을 만들고 각 서브플롯에 대해 dataframe에서 해당 data를 불러와서 그린다.
# create multiple scatter plots
from pandas import read_csv
from pandas import DataFrame
from pandas import concat
from matplotlib import pyplot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
values = DataFrame(series.values)
lags = 7
columns = [values]
for i in range(1,(lags + 1)):
columns.append(values.shift(i))
dataframe = concat(columns, axis=1)
columns = ['t']
for i in range(1,(lags + 1)):
columns.append('t-' + str(i))
dataframe.columns = columns
pyplot.figure(1)
for i in range(1,(lags + 1)):
ax = pyplot.subplot(240 + i)
ax.set_title('t vs t-' + str(i))
pyplot.scatter(x=dataframe['t'].values, y=dataframe['t-'+str(i)].values)
pyplot.show()
Autocorrelation Plots
* -1<=자기상관계수<=1, 0의 값에 근접할수록 약한 상관관계, -1or1과 근접할수록 강한 상관관계
* 아래 예시를 통해 lag가 365*i일때 마다 높은 값을 보여준다 이는 월-일은 같지만 년도만 다를 때의 온도의 상관관계이기 때문이다.(365/2의 값또한 높은 값을 보이는데 이또한 비슷한 이유이다.)
# create an autocorrelation plot
from pandas import read_csv
from matplotlib import pyplot
from pandas.plotting import autocorrelation_plot
series = read_csv('daily-minimum-temperatures.csv', header=0, index_col=0,
parse_dates=True, squeeze=True)
autocorrelation_plot(series)
pyplot.show()

'Study > time series forecasting with python' 카테고리의 다른 글
| Chapter 7. 추가 내용 (0) | 2021.06.14 |
|---|---|
| Chapter 7. Resampling and Interpolation (0) | 2021.06.14 |
| Chapter 5. Basic Feature Engineering (0) | 2021.05.20 |
| Chapter 4. Load and Explore Time Series Data (0) | 2021.05.19 |
| Chapter 3. Time Series as Supervised Learning (0) | 2021.05.13 |