
Chapter 4에서는
* Pandas library를 사용하여 CSV 파일에서 Time Series dataset을 로드하는 방법
* date-times를 사용하여 로드된 data를 보고 요약 통계를 계산하는 방법
* 요약 통계 계산과 리뷰 방법에 대해서 배운다
* 여기서 pandas의 역할은 로드된 data를 보고 dataset을 탐색하고 더 잘 이해하기 위해 사용된다.
Daily Female Births Dataset
* 여기서는 Daily Female Births Dataset을 사용한다.
* https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-total-female-births.csv
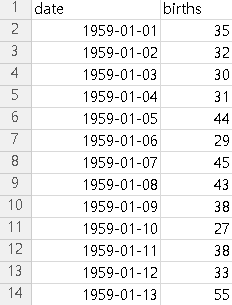
* 이 dataset은 위 sample과 같이 1959년도의 각 날짜 별 태어난 여성의 수를 설명한다.
Load Time Series Data
* pandas로 dataset을 time seires로 표현했다.
* 각 행에 대한 time label이 있는 1차원 배열이다.
* pandas에서 read_csv()함수를 사용하여 csv data load한다.
# load dataset using read_csv()
from pandas import read_csv
series = read_csv('daily-total-female-births.csv', header=0, index_col=0, parse_dates=True,
squeeze=True)
print(type(series))
print(series.head())* read_csv()의 param중 filepath_or_buffer='daily-total-female-births.cvs'는 읽고자하는 파일명으로 그 파일을 읽는 역할, url을 통해 파일을 읽어올 수 있다.
* header=0 은 읽고자하는 파일의 head를 어디로 지정하는가, 여기서는 0을 주어 0 행을 header로 지정
* index_col=0 은 첫 번째 열에(0번열) Time Series에 대한 인덱스 정보가 포함되어 있음을 알려주는 역할
* parse_dates=True 는 첫번째 열에 데이터를 구분하는 데 필요한 날짜가 포함되어 있다는 것을 알려주는 역할
* squeeze=True 는 데이터 열이 하나만 있으므로 Dataframe 대신 Series로 data를 load하는 역할
<class 'pandas.core.series.Series'>
Date
1959-01-01 35
1959-01-02 32
1959-01-03 30
1959-01-04 31
1959-01-05 44
Name: Births, dtype: int64* 이렇게 데이터를 로드하고 type(series)로 seires의 type, series.head()로 series의 위에서 5개의 data를 출력한다.
dataframe = DataFrame(series)* 위와 같이 코드를 작성함으로써, series로 생성된 dataset을 Dataframe으로 쉽게 변환가능하다.
Exploring Time Seires Data
* pandas는 Time Series data를 탐색하고 요약하는 도구도 제공한다.
Peek at the Data
* load된 data를 살펴보고 원하는 대로 load된 type, dates 등을 확인하는 것이 좋다.
* head() 함수를 사용하여 처음 5개의 data를 살펴 보거나, n개의 data를 지정할 수 있다.
# summarize first few lines of a file
from pandas import read_csv
series = read_csv('daily-total-female-births.csv', header=0, index_col=0, parse_dates=True,
squeeze=True)
print(series.head(10))
Date
1959-01-01 35
1959-01-02 32
1959-01-03 30
1959-01-04 31
1959-01-05 44
1959-01-06 29
1959-01-07 45
1959-01-08 43
1959-01-09 38
1959-01-10 27
Name: Births, dtype: int64* 또한, tail() 함수를 사용하면 마지막부터 n개의 data를 지정할 수 있다.
Number of Observations
* 관찰 횟수, 즉 data의 크기를 확인함으로써 데이터를 효과적으로 분할하는 방법에 대해 아이디어를 얻을 수 있다.
* 이는 size()함수를 통하여 확인할 수 있다.
# summarize the dimensions of a time series
from pandas import read_csv
series = read_csv('daily-total-female-births.csv', header=0, index_col=0, parse_dates=True,
squeeze=True)
print(series.size)
365
Querying By Time
* Time index를 사용하여 Series를 slice, dice, Querying할 수 있다.
* 아래의 예시는 1월의 모든 관측치를 엑세스하는 방법이다.
# query a dataset using a date-time index
from pandas import read_csv
series = read_csv('daily-total-female-births.csv', header=0, index_col=0, parse_dates=True,
squeeze=True)
print(series['1959-01'])
Date
1959-01-01 35
1959-01-02 32
1959-01-03 30
1959-01-04 31
1959-01-05 44
1959-01-06 29
1959-01-07 45
1959-01-08 43
1959-01-09 38
1959-01-10 27
1959-01-11 38
1959-01-12 33
1959-01-13 55
1959-01-14 47
1959-01-15 45
1959-01-16 37
1959-01-17 50
1959-01-18 43
1959-01-19 41
1959-01-20 52
1959-01-21 34
1959-01-22 53
1959-01-23 39
1959-01-24 32
1959-01-25 37
1959-01-26 43
1959-01-27 39
1959-01-28 35
1959-01-29 44
1959-01-30 38
1959-01-31 24
Name: Births, dtype: int64* 이러한 유형의 index기반 Querying은 dataset을 탐색하는 동안 요약 통계 및 플롯을 그리는데 도움이 될 수 있다.
Descriptive Statistics
* Time series에 대해 기술 통계를 계산하면 data에 대한 여러 정보를 얻을 수 있다.
from pandas import read_csv
series = read_csv('daily-total-female-births-in-cal.csv', header=0, index_col=0)
print(series.describe())* describe()함수를 통해 평균, 표준편차, 중간값, 최소, 최대값, 등을 얻을 수 있다.
count 365.000000
mean 41.980822
std 7.348257
min 23.000000
25% 37.000000
50% 42.000000
75% 46.000000
max 73.000000
Name: Births, dtype: float64
'Study > time series forecasting with python' 카테고리의 다른 글
| Chapter 6. Data Visualization (0) | 2021.05.27 |
|---|---|
| Chapter 5. Basic Feature Engineering (0) | 2021.05.20 |
| Chapter 3. Time Series as Supervised Learning (0) | 2021.05.13 |
| Chapter 2. What is Time Series Forecasting? (0) | 2021.05.13 |
| Chapter 1. Python Environment (0) | 2021.05.13 |