
Paper Info
논문 제목 : "Very Deep Convolutional Networks for Large-Scale Image Recognition"
저자 : Karen Simonyan, Andrew Zisserman
연도 : 2014
paper : https://arxiv.org/pdf/1409.1556
CNN Study Plan
CNN 분야의 발전에 큰 영향을 미친 다양한 연구들을 검토할 예정
model code : https://github.com/yeongjinHwang/CNN
- LeNet-5
paper review+code : https://gongjin-repository.tistory.com/67 - AlexNet
paper review : https://gongjin-repository.tistory.com/69 - VGGNet
paper review : https://gongjin-repository.tistory.com/73 - GoogLeNet
- ResNet
- DenseNet
- MobileNet
- EfficientNet
:: Background
VGGNet은 매우 깊은 네트워크 구조를 제안하며, 단순한 3x3 convolution filter를 쌓아 깊이 있는 model을 만드는 방식으로 성능을 향상시켰다.
0. Abstarct
very small(3x3) convolution filters architecture를 사용해서 incresing depth network 평가, depth를 16~19개의 weight Layer로 늘림으로써 이전 configuration에서 상당한 개선을 이룰 수 있음을 보여준다. 이 발견은 ImageNet Challenge 2024에서 localsation, classification에서 각각 1,2위를 하였다. 또한 추가 연구 촉진을 위해 가장 우수한 ConvNet model를 공개적으로 제공한다.
1. Introduction
GPU 성능 향상 및 Large-scale distributed clusters, ImageNet과 같은 large public image repositories 덕분에 Convolution Network는 최근 large-scale image, video recognition에서 큰 성공을 거두었다.
ILSVRC-2013에서 가장 우수한 submissions은 더 작은 receptive window size와 stride를 사용했다.
또한 전체 image와 여러 scale을 거쳐 network를 densely하게 training, testing한다.
해당 논문에서는 ConvNet Architecture design의 중요한 depth에 대해 다룬다.
이를 위해, 해당 논문에서는 Architecture의 다른 parameter를 고정하고, 모든 Layer에 3x3 Conv filter를 사용하여 더 많은 Convolution Layer를 추가함으로써 depth를 증가시킨다.
2. ConvNet Configurations
2.1. Architecture
ConvNets Input : 224x224x3(RGB) image
pre-processing : 각 pixel은 train set에서 계산된 평균 RGB값을 뺀다.
Conv Layers : receptive field : 3x3 (s=1, p=1 ==> 이를 통해 input의 resolution 유지한 채로 feature map 생성) 1x1 convolution filter도 사용하며, 이는 channels의 linear transformation이다.
Pooling Layer : max pooling, 2x2 filter (s=2 ==> input의 resolution을 반으로 줄이기) 다만, 모든 Conv Layer 이후 Pooling Layer가 있는것은 아님 (아래 테이블 참조)
FC Layer : 2개는 4096 channel, 세 번째는 1000-way ILSVRC classification == 1,000 channel
마지막으로 soft-max Layer ( FC Layer의 모든 구성은 같다)
모든 hidden Layer는 ReLU 사용
하나를 제외한 network의 어느 것도 LRN(Local Response-Normalization을 포함하지 않는다.
(성능은 향상할지라도, memory cost가 증가하므로 -> 이전 AlexNet을 비판하는 목적?)
2.2. Configurations
모든 Configuration은 위 2.1.을 따르며, depth만 다르다.
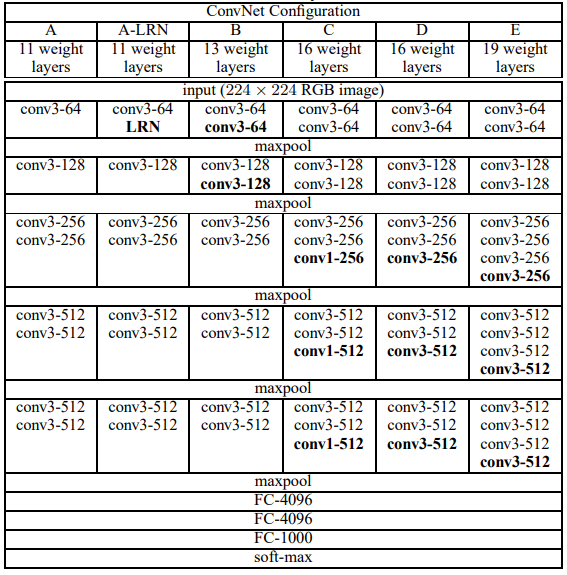
A : 11 weight Layer (Conv : 8, FC : 3), E : 19 weight Layer (Conv : 16, FC: 3)
위의 사진을 통해 conv 개수를 확인할 수 있으면 모든 network는 FC는 3으로 고정되어있다.
channel은 1 Layer에서 @64로 시작하여 마지막 Layer에서 @512로 끝난다. (output feature map 수를 channel로 표기한 것 같다)

2.3. Discussion
receptive feild를 크게 함으로써 빠르게 feature map size를 줄이는 것과 receptive feild를 작게 하는 대신 여러 번 수행하여 천천히 feature map을 줄이는 것의 차이를 설명한다.
to do..
'Study > CNN' 카테고리의 다른 글
| [AlexNet] ImageNet Classification with Deep ConvolutionalNeural Networks (0) | 2024.08.09 |
|---|---|
| [LeNet-5] GradientBased Learning Applied to DocumentRecognition (0) | 2024.08.09 |
| Background. 현재 나의 지식 (1) | 2024.08.07 |