
Paper Info
논문 제목 : "ImageNet Classification with Deep ConvolutionalNeural Networks"
저자 : Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hiniton
연도 : 2012
paper : https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
CNN Study Plan
CNN 분야의 발전에 큰 영향을 미친 다양한 연구들을 검토할 예정
model code : https://github.com/yeongjinHwang/CNN
- LeNet-5
paper review+code : https://gongjin-repository.tistory.com/67 - AlexNet
paper review : https://gongjin-repository.tistory.com/69 - VGGNet
- GoogLeNet
- ResNet
- DenseNet
- MobileNet
- EfficientNet
:: Background
AlexNet은 2012년 ImageNet 대회에서 압도적인 성능을 기록하며 CNN의 부활을 이끈 논문이다. ReLU 활성화 함수, 드롭아웃, GPU 사용 등의 혁신적인 기술을 도입했다.
0. Abstarct
ImageNet LSVRC-2000대회에서 1.2백만의 high-resolution images를 서로 다른 class로 분류하기 위해 large, deep convolution netwrok를 훈련했다. test data의 경우, top-1, top-5 error rate가 37.5%, 17.0%로 상당히 우수한 성과를 보였다.
60백만 parameter와 650,000 뉴런을 갖는 neural network로써, 5개의 convolutional layers(일부는 max-pooling layer를 따르는)와 최정적으로 3개의 1000-way softmax를 갖는 fully connected layers로 구성되어있다.
훈련 속도를 높이기 위해 non-saturation(비포화) neurons와 매우 효율적은 GPU 기반의 convolution operation을 사용했다.
non-saturation / saturation은 activation function에 있어서 나오는 개념이다.
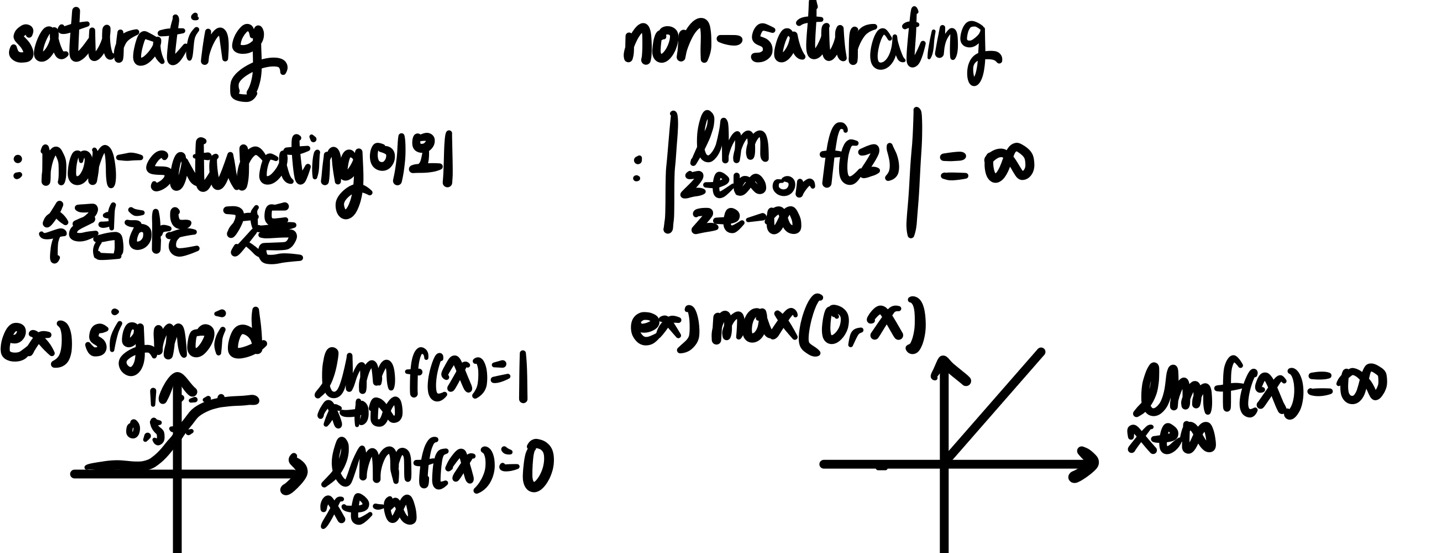
당연하게도 해당 논문에서는 ReLU를 사용했기 때문에 오른쪽 max(0,x)꼴이므로 non-saturating이다.
그렇다면 CNN관점에서 봤을 때, non-saturating이면 무엇이 좋을까,왜 train 속도가 향상될까?
sigmoid와 ReLU를 대표적으로 비교하면 미분했을 경우 sigmoid와 같이 -inf, inf로 갈수록 수렴하기에 미분값이 0에 가까워 진다. 이는 Back Propagation과정에서 gradient가 점점 작아지며 학습이 잘 이루어지지않는다는 것이다. (gradient update가 매우 작은 step을 가지기 때문에), 반면에 ReLU의 경우 양수는 항상 미분값이 1이므로 양수만 봤을 때는 gradient venishing문제가 없다.
fully-connected layers에서는 overfitting을 줄이기위해 "dropout" regularization method를 사용했다. (이는 효과적임을 해당 논문을 통해 확인 가능)

다음과 같이 일반적인 Neural Network와 Dropout적용한 network가 있다고 하자 (Input, Hidden Layer)
여기서 노드를 삭제하는 것을 "Dropout"이라고 하는데,
p=0.4일 경우 40%의 node를 Forward Propagation할 때, 삭제하는 것을 뜻한다.
각 Layer마다 5개의 node가 존재한다(오른쪽 그림 확인) 각각의 40%는 2이며 따라서 2개의 node를 삭제한다. 이는 Input Layer, Hidden Layer 모두에 적용된다. 이는 Batch마다 수행된다.

dropout관련 논문을 찾아보면 Overfitting된 것과 Dropout의 feature map을 확인하면,
위의 그림과 같이 Dropout Method를 적용한 것이 feature map이 더 확실하게 보인다.
이는, 연결(units간 feature 관계)는 줄어들었지만, 일반화에 더 잘 집중되었다고 볼 수 있다.
1. Introduction
현재 machine learning methods들의 성능을 향상시키기 위해, larger dataset을 수집하고, overfitting을 preventing하기 위해 더 나은 기술을 사용가능하다. (아마 Abstract에서 서술한 Dropout을 말하는 것 같다.)
MNIST문제의 경우 현재 오류률이 인간 성능에 근접하지만, 현실적으로 객체는 많은 변동성을 보이므로 훨씬 더 큰 데이터셋이 필요하다.
따라서 new dataset은 수십만 개의 fully-segmented image로 구성된 LabelMe, 22,000 이상의 카테고리 에서 15 백만의 labeled high-resolution images로 구성된 ImageNet이 포함된다.
CNN은 여전히 high-resolution images에 large scale로 적용하는 것은 매우 cost가 많이 든다.
위의 내용의 현실적인 문제들을 바탕으로 우리는 다음을 수행한다.
1. 2d convolution 최적화 GPU 구현 및 공개
2. 성능 향상 및 train 시간을 줄이는 여러 새로운 기능 포함
3. 120만 개의 라벨이 지정된 큰 dataset임에도 불구하고 overfitting preventing을 위한 효과적인 기술 사용
4.5개의 convolution layer, 3개의 fully-connected layer로 구성, 해당 구성에서 어떠한 convolution layer를 제거하더라도 성능이 저하 (최적화된 convolution layer 설계)
2. The Dataset
ImageNet은 22,000개의 카테고리, 15백만의 labeled high-resolution images dataset이다.
이미지가 어디서 수집했는가에 대해 적혀있으며 1.2백만 training images, 50,000의 validation images, 150,000 testing images를 사용했다고 한다. 이전 LeNet paper와 달리 여기서는 validation이 추가되었다.
그렇다면 model training에 있어서 validation은 언제 왜 생겨난 것일까?
validation dataset을 사용한 model hyper-parameter를 tuning하는 방법은 1990년대부터 ML Community를 통해 확산되다가 2000년대 초반부터 complex model들이 등장함에 따라 표준적인 방법으로 자리 잡았다.

추가적으로, label이 test dataset에 모두 존재할 수 있으나 kaggle같은 곳을 확인하면 train dataset에만 label이 존재하는 dataset들이 있다. 이 경우 train을 통해 model을 학습하고 parameter가 최적화되어있는지 모르는 상태로 test를 바로 수행하게 된다. 이 점에 있어서 validation dataset을 train에서 분할하여 parameter tunning함으로써 더 일반화된 model을 생성할 수 있다. 따라서, LeNet 등장 당시와 비교하여 validation dataset을 구축하는 것에 대한 이론이 적립이 된 상태이므로 해당 과정을 수행했다고 본다.
ImageNet은 다양한 resolution image로 구성되어 있지만, AlexNet은 256x256 고정 resolution으로 downsampling한다.
직사각형 image의 경우, 짧은 변을 256이 되도록 rescaling하고, 중앙 256x256을 image로 사용했다.
pixel의 원시 RGB값을 사용하여 network를 train했다. ( 중앙 pixel 기준 256x256 가져오는 것빼곤 전처리안했다)
3. Architecture
3.1. ReLU Nonlinearity

non-saturating nonlinearlity로써 ReLU를 사용하여 빠른 학습률을 보였다. 비교하는 점선은 tanh이다.
3.2. Training on Multiple GPUs
하나의 GTX 580 GPU의 경우 memory가 3GB이므로 본 논문에서는 하나의 network에 대해 2개의 GPU에 나눠서 training,
GPU parallelization은 kernel을 반으로 나눠 각각 하나의 GPU에 할당, 추가로 GPU Communication은 특정 layer에서만 발생하도록 하였다. 따라서 Layer 3에서 Layer 2의 모든 kernel map을 받아올 수 있지만, Layer 4의 경우 같은 GPU의 입력만 받아오게 된다.
3.3. Local Response Normalization
ReLU는 saturating을 prevent하기 위해 input normalization을 필요로 하지않는다.
적어도, 일부 training examples이 ReLU의 possitive input이면, neuron은 training한다.
그러나, 해당 논문에서는 local normalization scheme가 generalization에 도움되는 것을 발견

(x,y)의 위치에서 kernel i를 적용한 후에, ReLU를 적용하여 계산
( k=2, n=5, alpha = 10^(-4), beta=0.75 사용 )
N : layer 총 kernel 수
a : (x,y) 위치에서 kernel i를 적용한 다음 ReLU를 통과한 output 이라고 한다.
해당 수식에서 n을 통해 얼마나의 인접한 kernel을 sum할 지 결정한다. ( padding을 추가하지 않으므로 max, min을 사용한 것으로 보인다)
3.4. Overlapping Pooling
CNN의 pooling layer는 같은 kernel map에서 이웃한 neurons group의 outputs을 요약한다.
전통적으로는 pooling units으로 요약된 영역은 겹치지 않는다(stride를 filter size 이상, 보통은 같게 함으로써 같은 filed에 있는 data는 2번의 연산이 적용되지 않는 것은 뜻하는 것 같다.)
AlexNet은 s=2, z=3으로 설정했다. ( s : stride, z : 인접 영역 )
따라서 구석에 있는 data가 아닌 경우 1개씩 겹치게 했는데, 이는 구석의 데이터를 제외하고 주변의 local data를 더 많이 표현하기에 더 좋은 정확도가 나온것으로 보인다.
(z를 동일하게 하고 s를 작게 할 수록 겹치는 영역이 많아지는데 그만큼 output feature map이 커지며 더 많은 정보를 나타내니까 당연하게도 overfitting이 되지않는다는 전제를 갖는다면, 정확도가 높아질 것으로 생각, 하지만, 그만큼 training 속도가 감소할 것이다.)
3.5. Overal Architecture


다음은 fully-connected Layer 진입전을 설명한 그림이다.
Conv3,4,5 이후에는 LRN이 없으며 Conv5이후 max pooling을 거쳐 fully-connected Layer로 진입한다.
단, 해당 논문에서는 첫 Convolution Layer 1의 input을 224x224x3으로 표기해두었으나,
Convolution Layer 1 의 output size(55x55x1)를 토대로 계산해보면, 227x227x3이 정확하다.
추가적으로, padding에 대한 언급이 없는데 각 Layer마다의 Output Size를 일치시키기 위해서는 그림과 같이 각 Layer에 padding이 있어야되는 것을 알 수 있다,
마지막 fully-connected Layer의 output은 1,000개의 class label에 대한 distribution을 생성하는 1000-way softmax에 입력
따라서 최종적으로 1,000개의 label중 확률 상 가장 높은 class를 뽑게 될 것이다.
4. Reducing overfitting
AlexNet은 60 millions parameter를 가지고 있다.
LSVRC : 1,000 class, image label에 있어서 2^10(1,024)개를 mapping하는 것 또한 60 millions parameter를 학습 하는 것에 있어서 overfitting이 생길 수 있음, 따라서 아래의 2가지 방법을 추가적으로 사용한다.
4.1. Data Augmentation
연산할 때 바로바로 처리함으로써 input image data를 추가할 수 있다.
image를 처리하는 것은 우선, 256이 되도록 rescaling하고, 중앙 256x256을 image로 사용한다고 앞서 설명했다.
해당 image를 통해 Augmentation을 수행하게 될 텐데, image를 Augmentation하여도 label은 같기때문에 수행 가능한 것이다.
32x32x2=2,048배만큼 데이터를 늘릴 수 있다고 하는데 이를 통해 rotation=32, translation=32, horizontal flip=2번 수행하는 것을 알 수 있다. 이렇게 변형된 데이터는 224x224 patch를 얻어내서 입력으로 사용한다는데, 앞의 Architecture에서 224로 image size를 input할 시 size 문제가 생김으로써 227이 정확하다는 것을 알았다. 따라서 224x224 patch가 아닌 227x227 patch를 얻어낼 것이다.
Test 시에는, softmax Layer에서 꼭지점 4부분의 224x224 patch와 중앙 patch로써 총 5개의 patch, 그리고 horizontal flip을 통해 뽑은 5개의 patch로써 총 10개의 patch에 대해 평균을 구해서 예측을 수행한다.
두 번째로, RGB channel의 색상 강도를 조절한다.

PCA를 진행하고 mean=0, std=0.1, gaussian distribution에서 random variable을 추출한 후, 원래의 픽셀 값에 곱해주어 색상의 변형을 주는 방법이다. 색상이 다르더라도 label은 같다는 것을 통해 수행가능하다.
4.1. Dropout
이는 앞의 Abstract에서 설명한 것을 참조하면 된다.
이후는 learnning rate, batch size 등에 대한 설명이다.
...
짧은 논문이지만 여러 method를 다른 CNN model에 적용함으로써 해당 method가 얼마나 강력한 지 보여주는 논문으로 보인다. 하지만, 당시 GPU성능이 지금에 비해 많이 떨어지기에, GPU 2개를 사용함에 따라 다른 GPU끼리 연산하는 과정은 서로 관련성이 떨어질 것으로 보인다. 추가적으로 서로 다른 GPU 연산을 수행함에 있어서 여러 과정을 반복하면 서로 연관성이 떨어질 우려가 있어서인지 중간중간 통신을 하는데, 되게 신박한 idea인거 같다. 지금으로써는 GPU 성능이 매우 좋아서 생각하지 않아도 될 부분이지만, 그럼에도 불구하다면, 해당 방법론을 적용시켜보는 것도 좋을 것 같다.
'Study > CNN' 카테고리의 다른 글
| [VGGNet] Very Deep Convolutional Networks for Large-Scale Image Recognition (0) | 2024.08.12 |
|---|---|
| [LeNet-5] GradientBased Learning Applied to DocumentRecognition (0) | 2024.08.09 |
| Background. 현재 나의 지식 (1) | 2024.08.07 |