
Chapter 16에서는
* machine learning model을 평가하는 방법의 한계와 sample data에서 model을 평가해야하는 이유
* model 평가를 위해 time series data의 train-test split 및 multiple train-test split을 만드는 방법
* walk-forward 유효성 검사가 time series에 대한 machine learning model의 평가를 제공하는 방법에 대해 배운다.
Model Evaluation
* time series forecasting을 위해 model을 평가할 때, model training을 하는 데 사용하지 않은 data에 대한 model 성능에 관심이 있다.
* 이것을 sample data라고 부른다.
* 이미 알고 있는 data에 대한 예측은 완벽할 것이기 때문에, sample data를 사용해야된다.
* sample data는 train-test data split을 통해 생성할 수 있다.
* 하지만, 그중 대표적은 k-fold교차검증은 data가 독립적이라고 가정하기에 time series에 직접적으로 사용은 불가능하다.
* time series는 관측치간 관계가 있기때문이다.(trend or seasonality에 대해 non-stationary하다면, 관측치간 시간에 대해 관계가 있기 때문이다.)
* time seires problem에서 machine learning backtest하는 데 사용할 수 있는 세 가지 방법
* 1. 관측의 시간적 순서를 따르는 train-test split
* 2. 관측의 시간적 순서를 따르는 multiple train-test split
* 3. 각 단계에서 새로운 data를 받을 때 마다 model update 가능한 Walk-Forward Validation
Monthly Sunspots Dataset
* Monthly Sunspots dataset은 230년(1749-1983)이 조금 넘는 기간동안 관측된 흑점 수의 월별 개수에 대한 dataset
* 총 2820개의 관측치가 있다.
* https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-sunspots.csv
# Load sunspot data
from pandas import read_csv
from matplotlib import pyplot
series = read_csv('sunspots.csv', header=0, index_col=0)
print(series.head())
series.plot()
pyplot.show()
Sunspots
Month
1749-01 58.0
1749-02 62.6
1749-03 70.0
1749-04 55.7
1749-05 85.0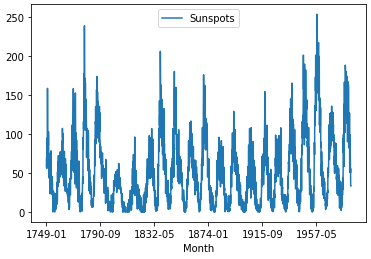
Train-Test Split
* 필요한 data의 양에 따라 분할을 50-50 / 70-30 / 90-10 등을 할 수 있다. 보통 66-34 split을 한다.
* dataset을 read하고 전체 index에서 앞부분의 66%를 train, 뒷부분의 34%의 data를 test data로 split을 하는 코드이다.
# calculate a train-test split of a time series dataset
from pandas import read_csv
series = read_csv('sunspots.csv', header=0, index_col=0, parse_dates=True, squeeze=True)
X = series.values
train_size = int(len(X) * 0.66)
train, test = X[0:train_size], X[train_size:len(X)]
print('Observations: %d' % (len(X)))
print('Training Observations: %d' % (len(train)))
print('Testing Observations: %d' % (len(test)))
Observations: 2820
Training Observations: 1861
Testing Observations: 959* 위의 코드에서 plotting에 대한 코드를 추가한 예제이다.
# plot train-test split of time series data
from pandas import read_csv
from matplotlib import pyplot
series = read_csv('sunspots.csv', header=0, index_col=0, parse_dates=True, squeeze=True)
X = series.values
train_size = int(len(X) * 0.66)
train, test = X[0:train_size], X[train_size:len(X)]
print('Observations: %d' % (len(X)))
print('Training Observations: %d' % (len(train)))
print('Testing Observations: %d' % (len(test)))
pyplot.plot(train)
pyplot.plot([None for i in train] + [x for x in test])
pyplot.show()
Observations: 2820
Training Observations: 1861
Testing Observations: 959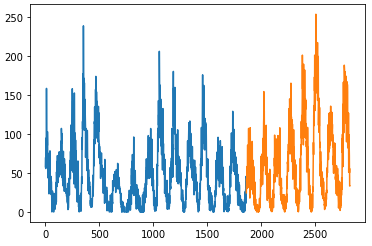
Multiple Train-Test Splits
* Time Series을 Train-Test set으로 split하는 과정을 여러번 반복할 수 있다.
* python에서 TimsSeriesSplit()이라는 함수를 사용하여 Multiple Train-Test Splits을 가능케한다.
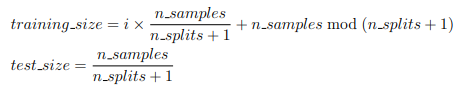
* n_samples는 총 관측치 수, n_splits은 총 분할 수
* 위의 식을 토대로 TimeSeriesSplit이 수행된다.
# calculate repeated train-test splits of time series data
from pandas import read_csv
from sklearn.model_selection import TimeSeriesSplit
from matplotlib import pyplot
series = read_csv('sunspots.csv', header=0, index_col=0, parse_dates=True, squeeze=True)
X = series.values
splits = TimeSeriesSplit(n_splits=3)
pyplot.figure(1)
index = 1
for train_index, test_index in splits.split(X):
train = X[train_index]
test = X[test_index]
print('Observations: %d' % (len(train) + len(test)))
print('Training Observations: %d' % (len(train)))
print('Testing Observations: %d' % (len(test)))
pyplot.subplot(310 + index)
pyplot.plot(train)
pyplot.plot([None for i in train] + [x for x in test])
index += 1
pyplot.show()
Observations: 1410
Training Observations: 705
Testing Observations: 705
Observations: 2115
Training Observations: 1410
Testing Observations: 705
Observations: 2820
Training Observations: 2115
Testing Observations: 705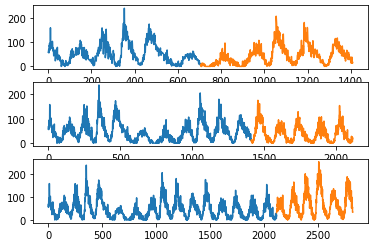
Walk Forward Validation

* 1. Minimum Number of Observations : 모델을 훈련하는 데 필요한 최소 관측치 수를 선택해야한다. (split 1의 training size)
* 2. Sliding or Expanding Window : 모델이 사용 가능한 모든 데이터에 대해 훈련 될 것인지 아니면 가장 최근의 관측에 대해서만 훈련 될 것인지 결정해야한다.
* Walk Forward Testing 또는 Walk Forward Validation이라고 부른다.
* 이 기능은 현재 scikit-learn에서 사용할 수 없지만 TimeSeriesSplit으로 동일한 효과를 만들 수 있다.
* modeling은 간단하지만, dataset이 큰 경우 문제가 될 수 있다.
# walk forward evaluation model for time series data
from pandas import read_csv
series = read_csv('sunspots.csv', header=0, index_col=0, parse_dates=True, squeeze=True)
X = series.values
n_train = 500
n_records = n_train+30
for i in range(n_train, n_records):
train, test = X[0:i], X[i:i+1]
print('train=%d, test=%d' % (len(train), len(test)))
train=500, test=1
train=501, test=1
train=502, test=1
train=503, test=1
train=504, test=1
train=505, test=1
train=506, test=1
train=507, test=1
train=508, test=1
train=509, test=1
train=510, test=1
train=511, test=1
train=512, test=1
train=513, test=1
train=514, test=1
train=515, test=1
train=516, test=1
train=517, test=1
train=518, test=1
train=519, test=1
train=520, test=1
train=521, test=1
train=522, test=1
train=523, test=1
train=524, test=1
train=525, test=1
train=526, test=1
train=527, test=1
train=528, test=1
train=529, test=1
'Study > time series forecasting with python' 카테고리의 다른 글
| Chapter 17. Forecasting Performance Measures (0) | 2021.07.21 |
|---|---|
| Chapter 15. Stationarity in Time Series Data (0) | 2021.07.21 |
| Chapter 14. Use and Remove Seasonality (0) | 2021.07.21 |
| Chapter 13. Use and Remove Trends (0) | 2021.07.21 |
| Chapter 12. Decompose Time Series Data (0) | 2021.07.12 |