D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
Peng, Yansong, et al. "D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement." arXiv preprint arXiv:2410.13842 (2024).
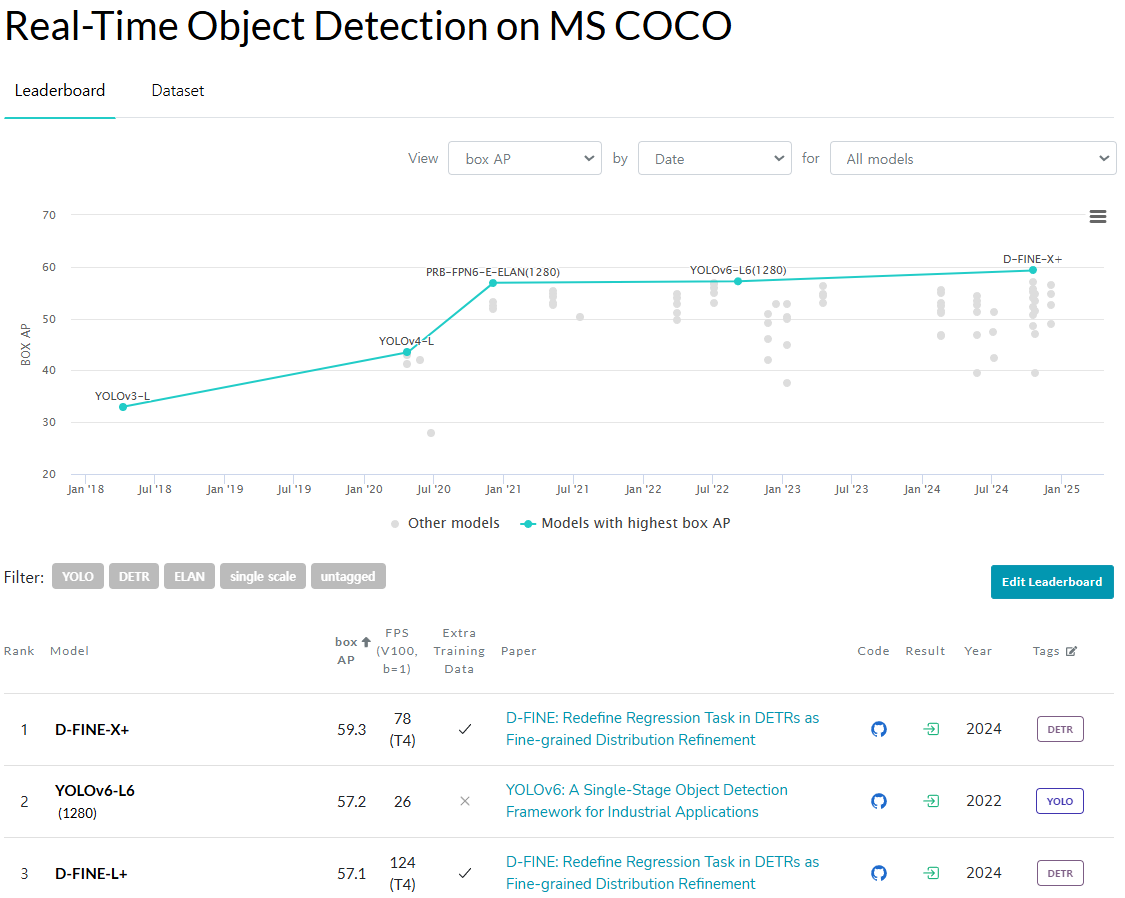
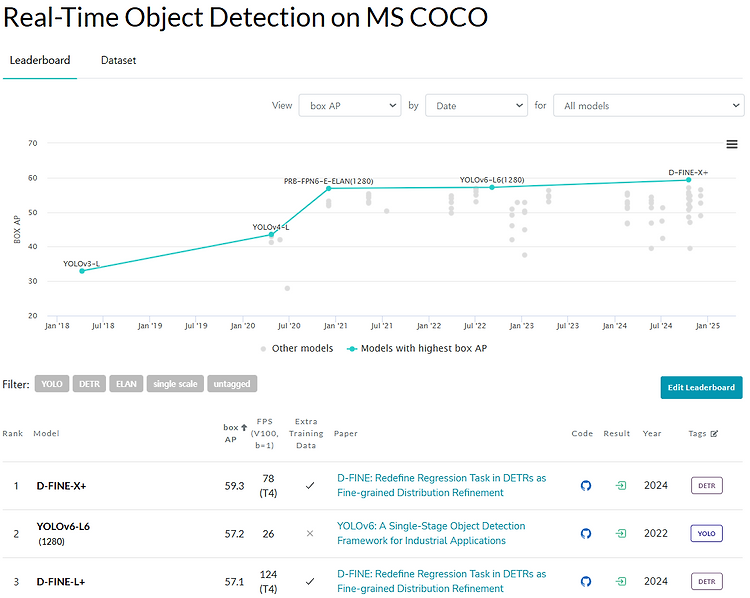
RT Detection SOTA D-fine에 대해 리뷰 진행.
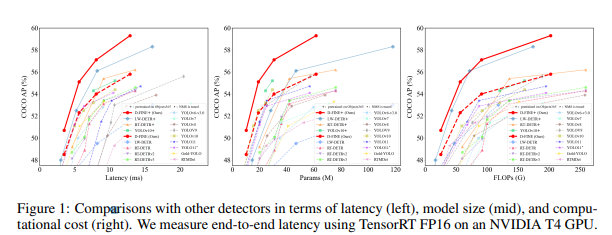
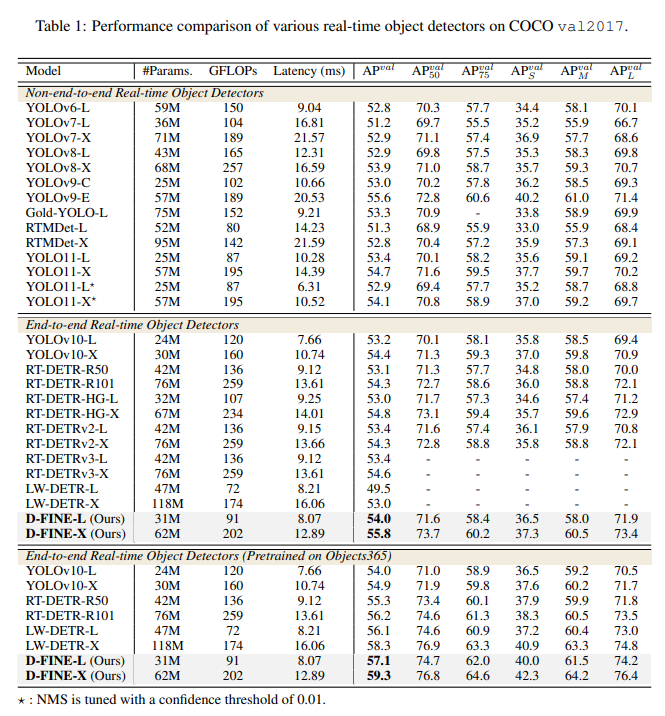
AP와 Latency 사이에서 둘 다 굉장히 우수한 DETR 기반의 RT Detector이다.
아마도 이 정도의 FPS와 box AP의 성능이라면,
End-to-End 방식이라는 점과 결합하여 Yolo를 밀어낼만한 충분한 detector라고 생각한다.
0. Abstract
D-FINE은 기존 DETR model에서의 bounding box regression task를 redefining하여 정밀한 object localization을 하는 powerful한 real-time object detector이다.
주요 구성 요소
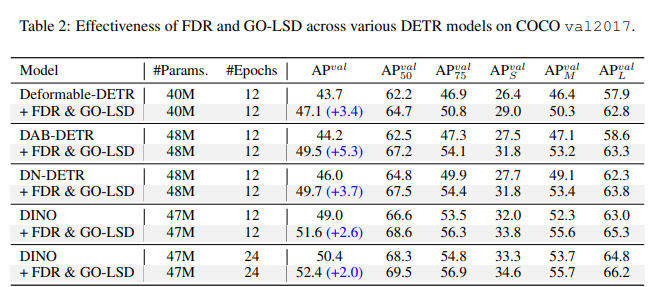
1. "Fine-grained Distribution Refinement(FDR)"
2. "Global Optimal Localization Self-Distillation (GO-LSD)"
FDR : regression process를 fixed coordinates predicting을 probability distributions로 반복적으로 변환.
GO-LSD : shallower layers와 deeper layers 간의 bidirectional optimization strategy을 통해 성능 향상.
이 방식은 더 가벼운 계산을 통해 기존 모델보다 높은 AP와 처리속도를 달성.
1. Introduction
real-time object detection은 YOLO 시리즈와 DETR 기반 RT-DETR, LW-DETR과 같은 model을 통해 발전.
아직 formulation of bounding box regression가 주요 과제로 남음.
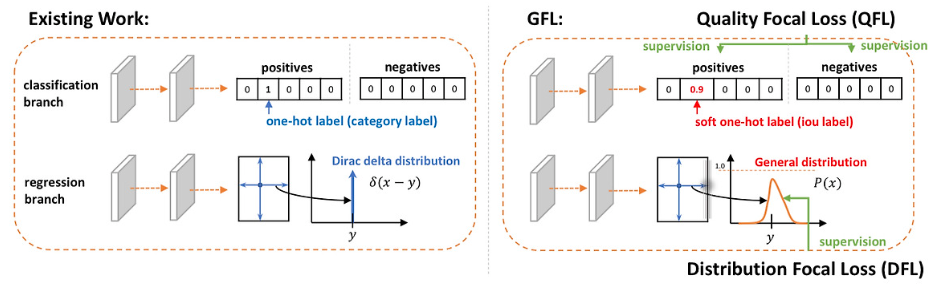
대부분 detector는 fixed coordinates를 regression하여 bounding box의 edges를 Dirac delta distribution으로 modeling된 값으로 처리한다. 이 접근 방법은 단순하지만, localization uncertainty한 것을 modeling하지 못한다.
localization uncertainty?
occlusion, blur와 같은 형태를 modeling하기에는 dirac delta distribution으로 modeling하는 것은 한계가 있음.
dirac delta distribution이 왜 한계가 있는가?

기존 bbox 추론은 대부분 object 중심을 기준으로, anchor에서 bbox의 각 변까지의 거리에 해당하는 sclar값들을 확률이 1인 Dirac delta distribution으로 나타낸다. 이는 즉, 기존 방식들은 distribution을 dirac delta로 가정하였다는 뜻이다.
하지만, localization uncertainty에 대한 형태는 확률 1이라고 볼 수 없다는 문제.
이를 해결하기 위해 다른 연구에서는 dirac delta distribution이 아닌, 기대값을 기반으로 추론하는 연구가 있다.
결과적으로, model은 각 모서리를 독립적으로 조정하는 데 충분하지 않은 L1 loss와 LoU loss를 사용하도록 제한된다.
(위의 4개의 sclar값을 통해)
이로 인해, optimization process에서 small coordinates changes에 민감해져 수렴 속도가 느려지고 성능이 최적화되지 못한다.
다른 과제로는 real-time detection의 효율성을 극대화하는 것이다.
(계산 자원 및 파라미터 예산이 적어지더라도 속도를 유지하는)
이 과제를 해결하기 위해 bounding box regression을 refining하고, 효과적인 self-distillation startegy를 도입한다.
이러한 접근 방식은 fixed coordinates regression에서 optimization, localization uncertainty modeling, 효율성 극대화 문제를 해결한다.
Fine-grained Distribution Refinement(FDR)을 도입하여 bounding box regression을 fixed coordinates를 예측하는 방식에서 probability distribution을 modeling하는 방식으로 변환
FDR은 residual 기반 방식으로 반복적으로 정제하여 점진적으로 더 세밀한 조정이 가능, localization precision 개선
deeper layer가 probability distribution 내에서 richer localization information을 포착하여, 더 정확한 예측을 한다는 것을 인지하여 Global Optimal Localization Self-Distillation(GO-LSD) 도입
deeper layer의 localization knowledge를 shallower layer로 transfer, 추가적인 trarning cost 거의 없다.
shallower layer의 prediction을 나중 layer의 refined ouput과 aligning하여 model을 초기 조정을 더 잘 수행하는 방법을 학습, 이는 수렴 속도를 가속화하고 전체 성능을 향상
2. Related work
skip
3. Preliminaries
Bounding box regression은 전통적으로 중심 기반 (x,y,w,h) 또는 모서리 거리(c,d) 형식을 사용하여
Dirac delta distribution을 modeling하는 방식에 의존해왔다. 여기서, 거리는 achor c={xc,yc}로 부터 거리 d={t,b,l,r)로 측정된다. 그러나 bounding box edge를 precise and fixed로 처리하는 Direc delta는 특히 ambiguous cases에 localization uncertainty modeling하기 어렵다.
이 rigid representation은 optimization을 제한할 뿐만 아니라, small prediction shifts에도 상돤한 localization errors 초래
이 문제를 해결하기 위해 GFocal은 achor point에서 4개의 point까지의 거리를 discretized probability distributions를 사용해 distance를 regress, bounding box에 더 flxible modeling 제공한다.
GFocal?
실제 distance d는 다음과 같이 modeling된다.

GFocal은 probability distribution을 통해 ambiguity, uncertainty를 처리하는 데 있어 한 걸음 나아갔지만, 여전히 문제 존재
1. anchor dependency : anchor없는 framework와의 호환성
2. No Iterative Refinement : prediction one shot without iterative, 따라서 reducing regression robustness
3. Coarse Localization : fixed distance ranges와 uniform bin 간격은 small object의 경우, 각 bin이 넓은 값 범위를 나타내기 때문에 coarse localization을 초래할 수 있다.
Localization distillation(LD)는 detection task에서 localization knowledge를 transfering하는 것이 효과적임을 보여주는 유망한 접근 방식임. GFocal을 기반으로 한 LD는 단순히 classification logits나 freature maps을 mimicking하는 대신 teacher model에서 가치있는 localization knowledge를 distilling함으로써 student model을 강화한다.
그럼에도 이 방법 또한 achor 기반 architecture에 의존하며 additional training costs 발생
4. Method
D-Fine은 Fine-grained Distribution Refinement와 Global Optimal Localization Self-Distillation 두 가지 주요 구성 요소를 활용하여 기존 bounding box regression의 단점을 해결하며, 거의 추가적인 parameter와 training cost 없이 성능을 크게 향상시켰다.
(1) Fine-grained Distribution Refinement (FDR)
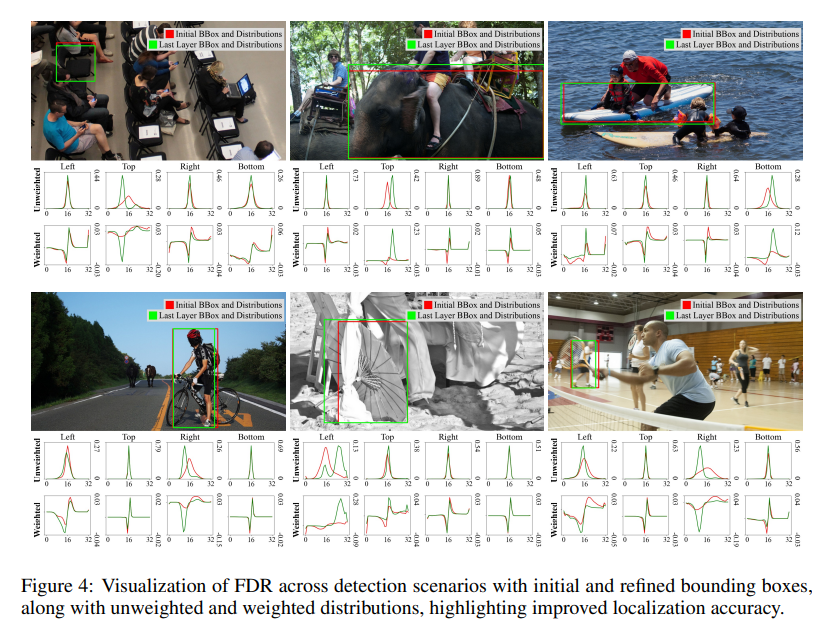
FDR은 bounding box prediction을 보정하는 역할을 하는 probability distributions를 iteratively하여 optimalization하여, 더 fine-grained된 intermediate를 제공한다.
이 접근법은 각 edge의 uncertainty를 independently하게 captures, optimizes한다.
non-uniform weighting function을 활용함으로써, FDR은 각 decoder layer에서 더 정밀하고 점진적인 조정을 가능하게 하여 localization accuracy를 개선하고, prediction errors를 줄인다.
FDR은 anchor가 없는 end-to-end framework 내에서 작동하여 더 flexible, robust optimization process를 가능하게한다.
(2) Global Optimal Localization Self-Distillation (GO-LSD)
refined distributions로 부터 얻은 localization knowledge를 shallower layer로 distills한다.
training progresses에 다라, final layer은 점점 더 precise soft label을 생성한다.
shallower layer는 GO-LSD를 통해 이러한 label과 predictions을 align하여 더 정확한 predictions를 제공한다.
early-stage predictions imporve에 따라, subsequent layers는 smaller residual을 refining하는 데 집중할 수 있다.
이를 통해 점진적으로 더 정확한 localization을 제공한다.
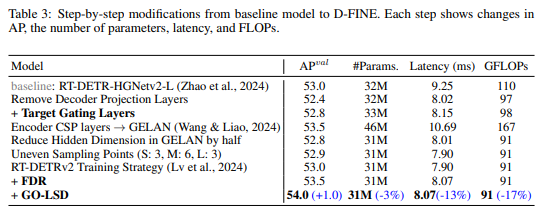
경량화는 일반적으로 성능 저하를 초래하지만, FDR과 GO-LSD는 성능 저하를 효과적으로 완화하며 경량화괸 모델을 제공하도록 하였다.
4.1. Fine-grained Distribution Refinement
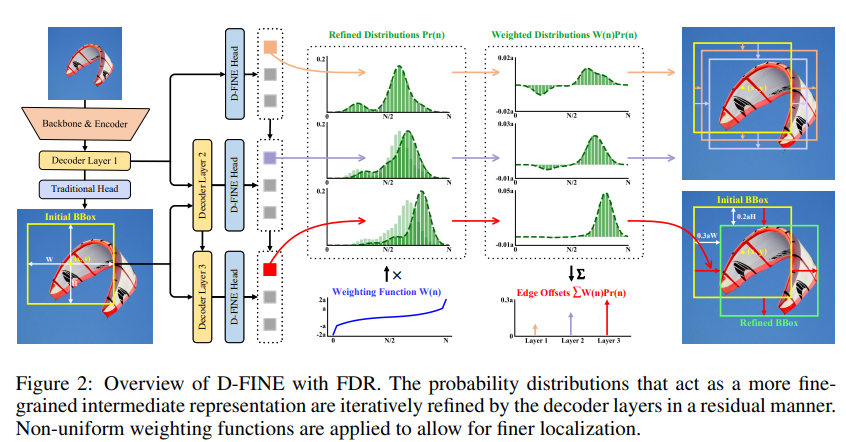
FDR은 decoder layer에서 생성된 fine-grained distribution을 interatively optimize한다.
initially, first decoder layer는 전통적인 bbox regression head와 D-Fine head를 통해 초기 bbox와 초기 probability distribution을 예측한다. (두 head는 MLP로, output dimension만 다르다.)
각 bbox는 4개의 distributions와 연결되며, 각 distribution은 edge에 해당한다.
초기 bbox는 reference box로 사용되며, 이후 layer에서 residual 방식으로 distribytion을 조정하고 이를 refining한다.
refined distributions는 이후 initial bbox의 four edge를 조정하는 데 사용되며, 반복할 수록 정확도 점직적 향상된다.
수학적으로 초기 bbox(b), 여기서 {x,y}는 center, {W,H}는 weight, height
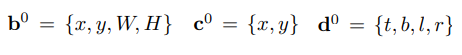
이를 통해 center(c)와 edge distance(d)로 변환할 수 있다.
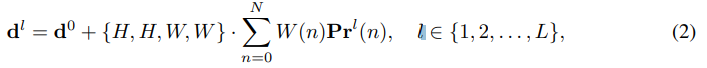
l번째 layer의 refined edge distance d는 (2)와 같이 계산된다. 여기서 P는 각 edge에 대한 separate distributions.
각 distributions는 해당 edge의 candidate offet values의 likelihood를 prediction.
candidates는 weight function W(n)에 의해 결정되며, n은 N개의 discrete bins 중 하나의 index를 나타내며, 각 bin은 potential edge offset에 해당한다.
edge offset은 초기 bbox H,W로 scaling되며, refined distributions은 residual 조정을 사용하여 update
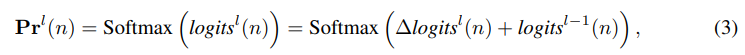
여기서 이전 layer의 logits은 four edge에 대한 각 bin의 offset value에 대한 신뢰도를 반영
현재 layer의 residual logit을 예측하며, 이를 이전 logit에 더해 update된 logit을 형성한다.
update된 logit은 softmax를 통해 normalization, 이를 통해 refined probabilty distributions 생성한다.
W(n)은 다음과 같이 정의된다.
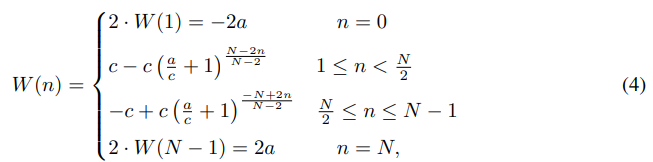
여기서 a와 c는 함수의 상환과 곡률을 제어하는 hyperparameter이다.
W(n)의 형태가 bbox의 prediction이 정확에 가까울 경우,
W(n)은 작은 곡률이 더 세밀한 조정을 가능하게 한다는 것을 보장한다.
W(n)에 대해 bbox 예측이 정확도가 낮은, 정확에서 먼 경우, W(n)의 edge 근처에서 더 큰 곡률과
경계에서 급격한 변화는 충분히 flexible을 제공하여 큰 수정을 가능하게 한다.
Distribution Focal Loss(DFL)에 영감받아, 새로운 손실 함수인 Fine-Grained Localization (FGL) Loss 제안
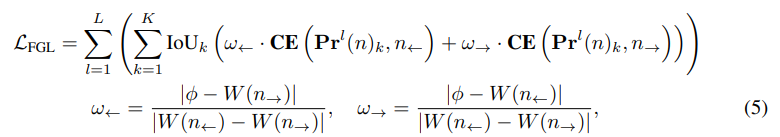
가중치 w<-, w->를 적용한 CE loss는 bin 사이의 interpolation이 ground truth offset과 precisely aligns하도록 보장.
4.2. Global Optimal Localization Self-Distillation (GO-LSD)
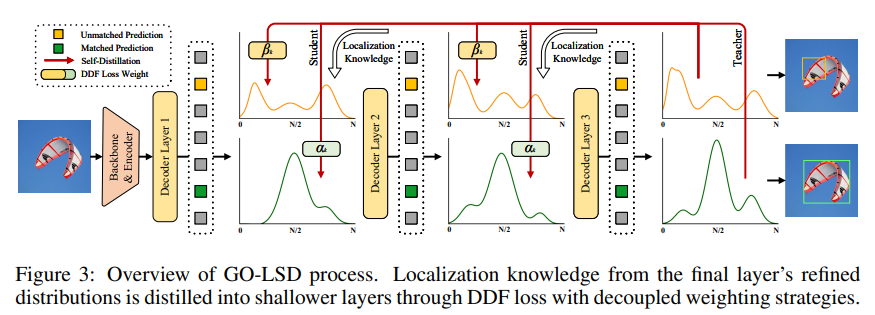
GO-LSD는 deeper layer에서 shallower layer로 localization knowledge를 transfer하도록 설계
이 과정은 Hungarian Matching을 각 layer의 prediction에 적용하여 model의 모든 stage에서 local bbox matching을 identifying하는 것으로 시작된다.
GO-LSD는 모든 layer의 match index를 통합된 union set으로 결합한다.
union set은 모든 layer에서 가장 정확한 후보 예측을 결합하여, 모든 layer가 distillation process에서 benefit을 받을 수 있도록 보장한다.
Golbal matching refined 외에, GO-LSD는 traing중 match되지 않은 prediction을 optimize하여, 성능을 향상시킨다.
localization은 union set을 통해 optimize, classification task는 1:1 matching principle, 중복된 bbox가 없도록 보장한다.
이러한 패턴은 union set에서 잘 localization되었지만, confidence score가 낮은 경우가 발생할 수 있다.
이를 해결하기 위해 Decoupled Distillation Focal(DDF) loss 도입,
높은 IoU를 가지지만 confidence가 낮은 prediction에 적절한 weight를 부여하여 분리된 weight strategies 적용
DDF loss는 또한 matching prediction과 non-matching prediction 양에 따라 기여도와 개별 loss를 균형있게 조절한다.
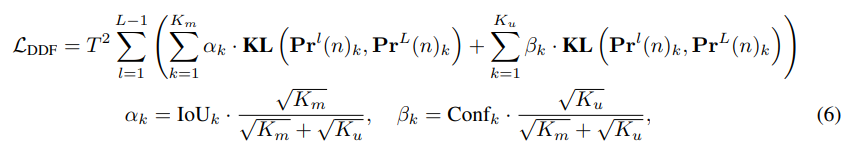
여기서, KL은 Kullback-Leiler 발산, T는 logit을 부드럽게 만드는데 사용되는 temperature parameter
k번째 matching prediction에 대한 distillation loss는 a_k에 의해 weighted,
K_m과 K_u는 각각 matching preidiction과 non-matching prediction 개수
k번째 non-matching prediction에 대해 B_k가 weight로 사용되며, classification confidence를 나타낸다.
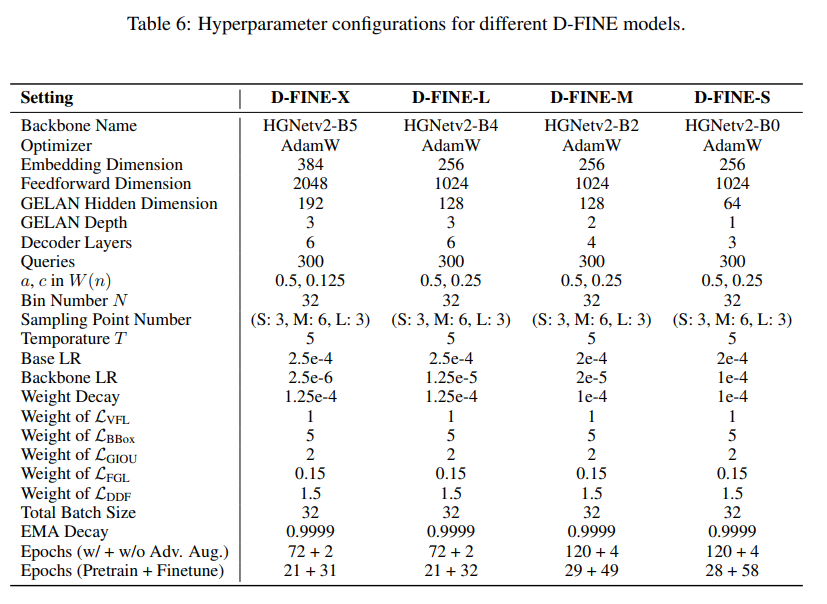
마지막으로 해당 D-Fine에 적용한 hyperparameter
'Study > computer vision' 카테고리의 다른 글
| BoostTrack++: using tracklet information to detect more objects in multiple object tracking (1) | 2024.12.13 |
|---|---|
| RT-DETR project (0) | 2024.12.13 |
| RT-DETR : DETRs Beat YOLOs on Real-time Object Detection (0) | 2024.12.11 |
| DETR : Inference code review (0) | 2024.12.10 |
| DETR : End-to-End Object Detection with Transformers (0) | 2024.12.10 |
D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement
Peng, Yansong, et al. "D-FINE: Redefine Regression Task in DETRs as Fine-grained Distribution Refinement." arXiv preprint arXiv:2410.13842 (2024).
RT Detection SOTA D-fine에 대해 리뷰 진행.
AP와 Latency 사이에서 둘 다 굉장히 우수한 DETR 기반의 RT Detector이다.
아마도 이 정도의 FPS와 box AP의 성능이라면,
End-to-End 방식이라는 점과 결합하여 Yolo를 밀어낼만한 충분한 detector라고 생각한다.
0. Abstract
D-FINE은 기존 DETR model에서의 bounding box regression task를 redefining하여 정밀한 object localization을 하는 powerful한 real-time object detector이다.
주요 구성 요소
1. "Fine-grained Distribution Refinement(FDR)"
2. "Global Optimal Localization Self-Distillation (GO-LSD)"
FDR : regression process를 fixed coordinates predicting을 probability distributions로 반복적으로 변환.
GO-LSD : shallower layers와 deeper layers 간의 bidirectional optimization strategy을 통해 성능 향상.
이 방식은 더 가벼운 계산을 통해 기존 모델보다 높은 AP와 처리속도를 달성.
1. Introduction
real-time object detection은 YOLO 시리즈와 DETR 기반 RT-DETR, LW-DETR과 같은 model을 통해 발전.
아직 formulation of bounding box regression가 주요 과제로 남음.
대부분 detector는 fixed coordinates를 regression하여 bounding box의 edges를 Dirac delta distribution으로 modeling된 값으로 처리한다. 이 접근 방법은 단순하지만, localization uncertainty한 것을 modeling하지 못한다.
localization uncertainty?
occlusion, blur와 같은 형태를 modeling하기에는 dirac delta distribution으로 modeling하는 것은 한계가 있음.
dirac delta distribution이 왜 한계가 있는가?
기존 bbox 추론은 대부분 object 중심을 기준으로, anchor에서 bbox의 각 변까지의 거리에 해당하는 sclar값들을 확률이 1인 Dirac delta distribution으로 나타낸다. 이는 즉, 기존 방식들은 distribution을 dirac delta로 가정하였다는 뜻이다.
하지만, localization uncertainty에 대한 형태는 확률 1이라고 볼 수 없다는 문제.
이를 해결하기 위해 다른 연구에서는 dirac delta distribution이 아닌, 기대값을 기반으로 추론하는 연구가 있다.
결과적으로, model은 각 모서리를 독립적으로 조정하는 데 충분하지 않은 L1 loss와 LoU loss를 사용하도록 제한된다.
(위의 4개의 sclar값을 통해)
이로 인해, optimization process에서 small coordinates changes에 민감해져 수렴 속도가 느려지고 성능이 최적화되지 못한다.
다른 과제로는 real-time detection의 효율성을 극대화하는 것이다.
(계산 자원 및 파라미터 예산이 적어지더라도 속도를 유지하는)
이 과제를 해결하기 위해 bounding box regression을 refining하고, 효과적인 self-distillation startegy를 도입한다.
이러한 접근 방식은 fixed coordinates regression에서 optimization, localization uncertainty modeling, 효율성 극대화 문제를 해결한다.
Fine-grained Distribution Refinement(FDR)을 도입하여 bounding box regression을 fixed coordinates를 예측하는 방식에서 probability distribution을 modeling하는 방식으로 변환
FDR은 residual 기반 방식으로 반복적으로 정제하여 점진적으로 더 세밀한 조정이 가능, localization precision 개선
deeper layer가 probability distribution 내에서 richer localization information을 포착하여, 더 정확한 예측을 한다는 것을 인지하여 Global Optimal Localization Self-Distillation(GO-LSD) 도입
deeper layer의 localization knowledge를 shallower layer로 transfer, 추가적인 trarning cost 거의 없다.
shallower layer의 prediction을 나중 layer의 refined ouput과 aligning하여 model을 초기 조정을 더 잘 수행하는 방법을 학습, 이는 수렴 속도를 가속화하고 전체 성능을 향상
2. Related work
skip
3. Preliminaries
Bounding box regression은 전통적으로 중심 기반 (x,y,w,h) 또는 모서리 거리(c,d) 형식을 사용하여
Dirac delta distribution을 modeling하는 방식에 의존해왔다. 여기서, 거리는 achor c={xc,yc}로 부터 거리 d={t,b,l,r)로 측정된다. 그러나 bounding box edge를 precise and fixed로 처리하는 Direc delta는 특히 ambiguous cases에 localization uncertainty modeling하기 어렵다.
이 rigid representation은 optimization을 제한할 뿐만 아니라, small prediction shifts에도 상돤한 localization errors 초래
이 문제를 해결하기 위해 GFocal은 achor point에서 4개의 point까지의 거리를 discretized probability distributions를 사용해 distance를 regress, bounding box에 더 flxible modeling 제공한다.
GFocal?
실제 distance d는 다음과 같이 modeling된다.
GFocal은 probability distribution을 통해 ambiguity, uncertainty를 처리하는 데 있어 한 걸음 나아갔지만, 여전히 문제 존재
1. anchor dependency : anchor없는 framework와의 호환성
2. No Iterative Refinement : prediction one shot without iterative, 따라서 reducing regression robustness
3. Coarse Localization : fixed distance ranges와 uniform bin 간격은 small object의 경우, 각 bin이 넓은 값 범위를 나타내기 때문에 coarse localization을 초래할 수 있다.
Localization distillation(LD)는 detection task에서 localization knowledge를 transfering하는 것이 효과적임을 보여주는 유망한 접근 방식임. GFocal을 기반으로 한 LD는 단순히 classification logits나 freature maps을 mimicking하는 대신 teacher model에서 가치있는 localization knowledge를 distilling함으로써 student model을 강화한다.
그럼에도 이 방법 또한 achor 기반 architecture에 의존하며 additional training costs 발생
4. Method
D-Fine은 Fine-grained Distribution Refinement와 Global Optimal Localization Self-Distillation 두 가지 주요 구성 요소를 활용하여 기존 bounding box regression의 단점을 해결하며, 거의 추가적인 parameter와 training cost 없이 성능을 크게 향상시켰다.
(1) Fine-grained Distribution Refinement (FDR)
FDR은 bounding box prediction을 보정하는 역할을 하는 probability distributions를 iteratively하여 optimalization하여, 더 fine-grained된 intermediate를 제공한다.
이 접근법은 각 edge의 uncertainty를 independently하게 captures, optimizes한다.
non-uniform weighting function을 활용함으로써, FDR은 각 decoder layer에서 더 정밀하고 점진적인 조정을 가능하게 하여 localization accuracy를 개선하고, prediction errors를 줄인다.
FDR은 anchor가 없는 end-to-end framework 내에서 작동하여 더 flexible, robust optimization process를 가능하게한다.
(2) Global Optimal Localization Self-Distillation (GO-LSD)
refined distributions로 부터 얻은 localization knowledge를 shallower layer로 distills한다.
training progresses에 다라, final layer은 점점 더 precise soft label을 생성한다.
shallower layer는 GO-LSD를 통해 이러한 label과 predictions을 align하여 더 정확한 predictions를 제공한다.
early-stage predictions imporve에 따라, subsequent layers는 smaller residual을 refining하는 데 집중할 수 있다.
이를 통해 점진적으로 더 정확한 localization을 제공한다.
경량화는 일반적으로 성능 저하를 초래하지만, FDR과 GO-LSD는 성능 저하를 효과적으로 완화하며 경량화괸 모델을 제공하도록 하였다.
4.1. Fine-grained Distribution Refinement
FDR은 decoder layer에서 생성된 fine-grained distribution을 interatively optimize한다.
initially, first decoder layer는 전통적인 bbox regression head와 D-Fine head를 통해 초기 bbox와 초기 probability distribution을 예측한다. (두 head는 MLP로, output dimension만 다르다.)
각 bbox는 4개의 distributions와 연결되며, 각 distribution은 edge에 해당한다.
초기 bbox는 reference box로 사용되며, 이후 layer에서 residual 방식으로 distribytion을 조정하고 이를 refining한다.
refined distributions는 이후 initial bbox의 four edge를 조정하는 데 사용되며, 반복할 수록 정확도 점직적 향상된다.
수학적으로 초기 bbox(b), 여기서 {x,y}는 center, {W,H}는 weight, height
이를 통해 center(c)와 edge distance(d)로 변환할 수 있다.
l번째 layer의 refined edge distance d는 (2)와 같이 계산된다. 여기서 P는 각 edge에 대한 separate distributions.
각 distributions는 해당 edge의 candidate offet values의 likelihood를 prediction.
candidates는 weight function W(n)에 의해 결정되며, n은 N개의 discrete bins 중 하나의 index를 나타내며, 각 bin은 potential edge offset에 해당한다.
edge offset은 초기 bbox H,W로 scaling되며, refined distributions은 residual 조정을 사용하여 update
여기서 이전 layer의 logits은 four edge에 대한 각 bin의 offset value에 대한 신뢰도를 반영
현재 layer의 residual logit을 예측하며, 이를 이전 logit에 더해 update된 logit을 형성한다.
update된 logit은 softmax를 통해 normalization, 이를 통해 refined probabilty distributions 생성한다.
W(n)은 다음과 같이 정의된다.
여기서 a와 c는 함수의 상환과 곡률을 제어하는 hyperparameter이다.
W(n)의 형태가 bbox의 prediction이 정확에 가까울 경우,
W(n)은 작은 곡률이 더 세밀한 조정을 가능하게 한다는 것을 보장한다.
W(n)에 대해 bbox 예측이 정확도가 낮은, 정확에서 먼 경우, W(n)의 edge 근처에서 더 큰 곡률과
경계에서 급격한 변화는 충분히 flexible을 제공하여 큰 수정을 가능하게 한다.
Distribution Focal Loss(DFL)에 영감받아, 새로운 손실 함수인 Fine-Grained Localization (FGL) Loss 제안
가중치 w<-, w->를 적용한 CE loss는 bin 사이의 interpolation이 ground truth offset과 precisely aligns하도록 보장.
4.2. Global Optimal Localization Self-Distillation (GO-LSD)
GO-LSD는 deeper layer에서 shallower layer로 localization knowledge를 transfer하도록 설계
이 과정은 Hungarian Matching을 각 layer의 prediction에 적용하여 model의 모든 stage에서 local bbox matching을 identifying하는 것으로 시작된다.
GO-LSD는 모든 layer의 match index를 통합된 union set으로 결합한다.
union set은 모든 layer에서 가장 정확한 후보 예측을 결합하여, 모든 layer가 distillation process에서 benefit을 받을 수 있도록 보장한다.
Golbal matching refined 외에, GO-LSD는 traing중 match되지 않은 prediction을 optimize하여, 성능을 향상시킨다.
localization은 union set을 통해 optimize, classification task는 1:1 matching principle, 중복된 bbox가 없도록 보장한다.
이러한 패턴은 union set에서 잘 localization되었지만, confidence score가 낮은 경우가 발생할 수 있다.
이를 해결하기 위해 Decoupled Distillation Focal(DDF) loss 도입,
높은 IoU를 가지지만 confidence가 낮은 prediction에 적절한 weight를 부여하여 분리된 weight strategies 적용
DDF loss는 또한 matching prediction과 non-matching prediction 양에 따라 기여도와 개별 loss를 균형있게 조절한다.
여기서, KL은 Kullback-Leiler 발산, T는 logit을 부드럽게 만드는데 사용되는 temperature parameter
k번째 matching prediction에 대한 distillation loss는 a_k에 의해 weighted,
K_m과 K_u는 각각 matching preidiction과 non-matching prediction 개수
k번째 non-matching prediction에 대해 B_k가 weight로 사용되며, classification confidence를 나타낸다.
마지막으로 해당 D-Fine에 적용한 hyperparameter
'Study > computer vision' 카테고리의 다른 글
| BoostTrack++: using tracklet information to detect more objects in multiple object tracking (1) | 2024.12.13 |
|---|---|
| RT-DETR project (0) | 2024.12.13 |
| RT-DETR : DETRs Beat YOLOs on Real-time Object Detection (0) | 2024.12.11 |
| DETR : Inference code review (0) | 2024.12.10 |
| DETR : End-to-End Object Detection with Transformers (0) | 2024.12.10 |