
2024.12.10 - [Study/SOTA paper] - DETR : End-to-End Object Detection with Transformers
Lib, Config
: Inference용도이기에 backpropagation gradient False
from PIL import Image
import requests
import matplotlib.pyplot as plt
%config InlineBackend.figure_format = 'retina'
import torch
from torch import nn
from torchvision.models import resnet50
import torchvision.transforms as T
torch.set_grad_enabled(False)Model
init
: backbone - ResNet50사용
: ResNet을 통한 feature map은 Transformer input하므로, FC layer delete
: ResNet 출력 feature map (c=2048)을 transformer hidden dim으로 축소하기 위해 1x1 conv layer
: 예측하기 위한 class와 비어있는 class 총 num_class+1개로 구성된 class prediction layer
: transformer 출력을 네 개의 좌표 변환하기 위한 box prediction layer
: positional embeding
class DETRdemo(nn.Module):
def __init__(self, num_classes, hidden_dim=256, nheads=8,
num_encoder_layers=6, num_decoder_layers=6):
super().__init__()
# create ResNet-50 backbone
self.backbone = resnet50()
del self.backbone.fc
# create conversion layer
self.conv = nn.Conv2d(2048, hidden_dim, 1)
# create a default PyTorch transformer
self.transformer = nn.Transformer(
hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
# prediction heads, one extra class for predicting non-empty slots
# note that in baseline DETR linear_bbox layer is 3-layer MLP
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
# output positional encodings (object queries)
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
# spatial positional encodings
# note that in baseline DETR we use sine positional encodings
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))Forward
: ResNet-50 Stage 1 -> Stage 2부터 4 -> 1x1 Conv Layer (Transformer hidden dim 크기 일치)
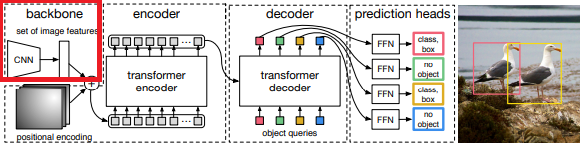
: Positional Encoding 생성 - 2D positional embeding
: flatten(2)로 2차원 이후 차원에 대해 합쳐서 height * width feature map을 1d vector 변환
: permute(2,0,1)로 tensor 차원 순서 변경해서 Transformer input
: 최종적으로 Transformer의 class 점수출력, box 점수 sigmoid로 0~1로 normalization해서 출력
def forward(self, inputs):
# propagate inputs through ResNet-50 up to avg-pool layer
x = self.backbone.conv1(inputs)
x = self.backbone.bn1(x)
x = self.backbone.relu(x)
x = self.backbone.maxpool(x)
x = self.backbone.layer1(x)
x = self.backbone.layer2(x)
x = self.backbone.layer3(x)
x = self.backbone.layer4(x)
# convert from 2048 to 256 feature planes for the transformer
h = self.conv(x)
# construct positional encodings
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
# propagate through the transformer
h = self.transformer(pos + 0.1 * h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1)).transpose(0, 1)
# finally project transformer outputs to class labels and bounding boxes
return {'pred_logits': self.linear_class(h),
'pred_boxes': self.linear_bbox(h).sigmoid()}Model pre-trained weight load
detr = DETRdemo(num_classes=91)
state_dict = torch.hub.load_state_dict_from_url(
url='https://dl.fbaipublicfiles.com/detr/detr_demo-da2a99e9.pth',
map_location='cpu', check_hash=True)
detr.load_state_dict(state_dict)
detr.eval();Class, visualization color define
skip
Pre-Processing, 출력 처리
: 짧은 size기준으로 800size로 resize
(작은 image에 대해 성능이 안좋아서?)
: image에 대해 정규화 (mean : [0.485, 0.456, 0.406], std : [0.229, 0.224, 0.225])
(pre-trained model과 scale 맞추려고?)
# standard PyTorch mean-std input image normalization
transform = T.Compose([
T.Resize(800),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# for output bounding box post-processing
def box_cxcywh_to_xyxy(x):
x_c, y_c, w, h = x.unbind(1)
b = [(x_c - 0.5 * w), (y_c - 0.5 * h),
(x_c + 0.5 * w), (y_c + 0.5 * h)]
return torch.stack(b, dim=1)
def rescale_bboxes(out_bbox, size):
img_w, img_h = size
b = box_cxcywh_to_xyxy(out_bbox)
b = b * torch.tensor([img_w, img_h, img_w, img_h], dtype=torch.float32)
return bDetection
: image 전처리 수행 및 tensor 변환
: 크기 제한
: background or 비어있는 슬릇에 대해 제외, 신뢰도기반으로 높은것만 선택
def detect(im, model, transform):
# mean-std normalize the input image (batch-size: 1)
img = transform(im).unsqueeze(0)
# demo model only support by default images with aspect ratio between 0.5 and 2
# if you want to use images with an aspect ratio outside this range
# rescale your image so that the maximum size is at most 1333 for best results
assert img.shape[-2] <= 1600 and img.shape[-1] <= 1600, 'demo model only supports images up to 1600 pixels on each side'
# propagate through the model
outputs = model(img)
# keep only predictions with 0.7+ confidence
probas = outputs['pred_logits'].softmax(-1)[0, :, :-1]
keep = probas.max(-1).values > 0.7
# convert boxes from [0; 1] to image scales
bboxes_scaled = rescale_bboxes(outputs['pred_boxes'][0, keep], im.size)
return probas[keep], bboxes_scaledResult

'Study > computer vision' 카테고리의 다른 글
| RT-DETR project (0) | 2024.12.13 |
|---|---|
| RT-DETR : DETRs Beat YOLOs on Real-time Object Detection (0) | 2024.12.11 |
| DETR : End-to-End Object Detection with Transformers (0) | 2024.12.10 |
| [ResNet] Skip connection 제대로 이해 (1) | 2024.12.07 |
| pose estimation occlusion problem related works (1) | 2024.11.29 |