
이전에 데이터셋을 분석-적용할 수 있다고 생각했던 부분은 다음과 같다.
1. 비정상적인 경기 패턴
- 킬 방생 시간과 골드 차이 데이터를 기반으로 어떤 시간대에 많은 골드가 발생했는 지
- 어시스트와 킬 수를 비교해서 팀별 팀워크 집중도 탐지
VAE, Lsolation Forest, Autoencoder 등등
2. 어떤 팀이 승리할 지 예측
- 분단위로 되어 있는 데이터가 많기에 분단위로 쪼개서 승리 팀을 예측
- 블루/레드 팀의 분당 골드, 킬/데스 비율, 오브젝트 현황, 어느 라인에 골드가 많이 투자되었는 지 등
해당 Feature들 기반으로 학습하고 타임라인별로 승리를 예측
TabNet, XGBoost, ...등등
3. 경기 중 어느 시점에 킬이 많이 발생하는지, 오브젝트를 점령하는지, 골드 추세
- 골드 차이의 미래 추세 예측
- 킬/데스 시점 예측
- 오브젝트 점령 시간대 예측
- 시간별 feature와 그에 따른 event feature로 나누어서 하면 될거 같다.
시간성이 중요하니까, LSTM, GRU 등을 기반으로 or TCN, Transformer
4. 그럼 여기에 강화학습은 어떤 식으로 적용할까?
- 킬/데스, 오브젝트, 골드차이 등에 따른 reward 계산
: 이에 따른 action을 어떤식으로 취하여야 승률이 올라가는 지 예측
강화학습 쪽은 아는 모델/알고리즘이 제한적이라 추후 학습하면서 진행
승리 팀 예측 (2.)
: 1차적으로 어떤 팀이 승리할 지 예측하는 것 부터 시도한다.
: 학습을 통해 진행하고자 한다.
우선 어떤 feature들이 승률과 상관 관계가 있는지 부터 확인하고, 상관 관계가 높은 feature들을 학습하고자 상관 관계 검증부터 하였다.

블루팀 기준으로만 확인 했을 때,
골드 격차의 마지막 시점만 사용하였으며,
obj등은 시간으로 저장되어있어서 길이로써 몇 개를 먹었냐에 대해 검증하였다.
대체적으로 높은 수준의 상관관계가 있음을 확인했으며, 역시나 절대적인 gold보다는 상대적인 golddiff가 더욱 승/패에 연관성이 크다.
해당 기반으로 bResult와 상관관계가 0.5이상을 feature로써 사용하고
간단한 model을 구성
: 4개의 FC Layer (input -> 64 -> 32 -> 16 -> 1)
: activation function : ReLU
: output layer Sigmoid
: Adam optimization, BCE Loss (0~1 class라 0에 대해 loss 크게 계산하기 위해)
epoch 1당 해당 모델의 수행 과정

import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
# bResult와 상관관계가 0.5 이상인 피처들만 선택
threshold = 0.5
selected_features = correlation_matrix.columns[(correlation_matrix['bResult'].abs() >= threshold)].tolist()
# bResult는 목표 변수이므로 제외하고 선택된 피처만 사용
selected_features.remove('bResult')
# Feature와 Target 나누기 (선택된 피처만 사용)
X = data[selected_features]
y = data['bResult']
# 데이터 정규화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 훈련 및 테스트 데이터로 분리
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 데이터 텐서로 변환
X_train_tensor = torch.tensor(X_train, dtype=torch.float32)
X_test_tensor = torch.tensor(X_test, dtype=torch.float32)
y_train_tensor = torch.tensor(y_train.values, dtype=torch.float32).view(-1, 1) # 2D tensor로 변환
y_test_tensor = torch.tensor(y_test.values, dtype=torch.float32).view(-1, 1)
# 모델 구성 (PyTorch)
class Net(nn.Module):
def __init__(self, input_dim):
super(Net, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 16)
self.fc4 = nn.Linear(16, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = self.fc4(x)
return x
# 모델 인스턴스화
model = Net(input_dim=X_train_tensor.shape[1])
# 손실 함수 정의 (Binary Cross-Entropy Loss)
criterion = nn.BCELoss() # Log와 관련된 Loss
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 모델 훈련
epochs = 10000
losses = [] # loss를 기록할 리스트
for epoch in range(epochs):
model.train()
# 순전파
outputs = torch.sigmoid(model(X_train_tensor)) # Sigmoid 활성화 적용
loss = criterion(outputs, y_train_tensor)
# 역전파
optimizer.zero_grad()
loss.backward()
optimizer.step()
# loss 기록
losses.append(loss.item())
if (epoch + 1) % 10 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
# 학습된 loss 그래프 그리기
plt.plot(losses)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss per Epoch (BCELoss)')
plt.show()
더 큰 스케일로 봐야될 것 같다, 약 6천번의 epoch부터 수렴이 됐으며, 나는 10000epoch 수행했다.
위의 코드에서 분할한 test dataset을 기반으로 eval
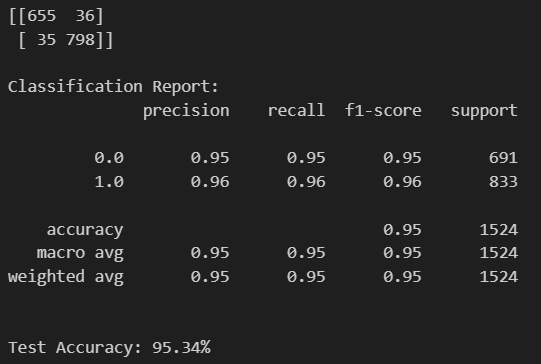
label(0) : blue 패배, label(1) : blue 승리
test case에 대해
TN case : 655, FP case : 36
FN case : 35, TP case : 798,
Precision : TP/(TP+FP) = 798/(798+36) = 0.95
Recall : TP/(TP+FN) = 798/(35+798) = 0.95
Accuracy : (TP+TN)/all
그럼 Layer를 더 쌓아서?
Layer adding model
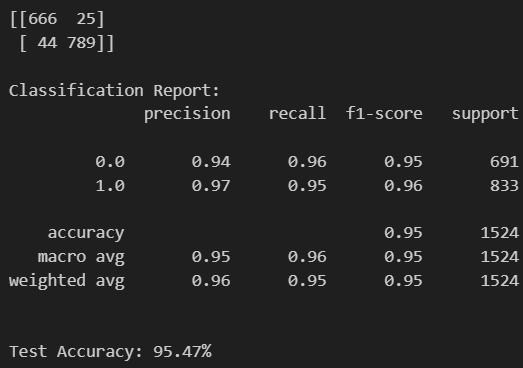
7개의 layer로 구성하고 했는데, 결과는 조금의 향상이 있었지만, 과연 문제가 없었을까?
feature나 data의 수가 그렇게 많지 않기에 overfitting문제나 augmentation이 필요하지않았을까?
우선, 해당 문제는 다음에 고민하기로 하고 xgboost로도 승리예측 수행
XGboost
feature engineering 이후 상관관계 기반 0.5이상의 feature들에 대해 학습을 하고 결과를 냈었다.
그런데 해당 feature들도 승리라는 것에 상관도는 다를것이며, 중요도를 계산하기 위해 XGboost 사용
XgBoost로 feature당 중요도를 계산

gold의 차이가 확실하게 중요도가 높게 나왔다.
XGBoost + Ours
XGboost로 구한 feature들의 importance들을 곱해주고 우리 모델을 학습하고 평가 시도
여기서 말하는 우리 모델은 초기 만들었던 FC layer 4개로 구성된 모델이다.
# 가중치 적용: 중요도를 각 특성에 곱하기
weighted_X_train = X_train_tensor.clone()
weighted_X_test = X_test_tensor.clone()
for i, weight in enumerate(importance):
weighted_X_train[:, i] *= weight
weighted_X_test[:, i] *= weight
# 모델 인스턴스화
input_dim = weighted_X_train.shape[1]
model = Net(input_dim=input_dim)
# 손실 함수 및 옵티마이저 정의
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 학습 과정
epochs = 10000
losses = []
for epoch in range(epochs):
model.train()
outputs = torch.sigmoid(model(weighted_X_train)) # Sigmoid 활성화 적용
loss = criterion(outputs, y_train_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.item())
if (epoch + 1) % 50 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
# 학습 손실 시각화
import matplotlib.pyplot as plt
plt.plot(losses)
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.title('Training Loss per Epoch')
plt.show()
# 평가
model.eval()
with torch.no_grad():
y_pred = model(weighted_X_test)
y_pred = torch.sigmoid(y_pred) # 확률값으로 변환
y_pred = y_pred.round() # 0 또는 1로 변환
# 정확도 계산
accuracy = (y_pred.squeeze() == y_test_tensor.squeeze()).sum().item() / len(y_test_tensor)
# 혼동 행렬 및 성능 평가
cm = confusion_matrix(y_test_tensor.squeeze(), y_pred.squeeze())
print("\nConfusion Matrix:")
print(cm)
print("\nClassification Report:")
print(classification_report(y_test_tensor.squeeze(), y_pred.squeeze()))
print(f"\nTest Accuracy: {accuracy * 100:.2f}%")

이전(95.34%)보다 96.39%로 정확도 약 1.1% 향상
추가적으로, 이렇게 학습된 모델을 기반으로
riot에서 게임중 데이터를 실시간으로 수집하며 승리/패배가 아닌 승률을 예측하는 것을 만들어보고 싶다.
(결과를 0~1 classification이 아닌 0~100 regression)
하지만, 이를 실시간적으로 보여준다면, 승률을 보고 너무 높으면 게임을 대충하는 등의 요소가 추가되니까 승률 추이가 실제와 많이 변동성이 있지 않을까?
따라서, 수집된 데이터를 기반으로 분단위로 어느정도 우세했는지
해당 게임을 분석할 때 추가적인 도움을 줄 수 있는 무언가를 만들 수 있을 것 같다.
++ 해당 feature들을 결합하여 하나의 2d image와 같이 (채널은 없겠지만) 하나의 array로 표현한 후
ConvNet을 수행함으로써 CNN기반으로 예측이 가능할 것 같다. 라는 생각을 하여 CNN기반으로 모델을 정의하고 수행해봐야겠다.
'Project > Data_Analysis' 카테고리의 다른 글
| 데이터셋 확보 및 진행 (1) | 2024.12.05 |
|---|---|
| 롤이 너무 좋아서 riot api를 사용하기로 했다. (0) | 2024.06.28 |