
카테고리
1. Data Augmentation Techniques
1-1-1: Synthetic occlusion generation during training
1-1-2: Randomized part masking to improve model robustness
1-1-3: Introducing artificial occlusion patterns in training datasets
2. Advanced Neural Network Architectures
2-1-1: Multi-branch networks with occlusion-aware feature extraction
2-1-2: Attention mechanisms that can handle partially occluded body parts
2-1-3: Transformer-based models with self-attention capabilities
3. Probabilistic and Ensemble Methods
3-1-1: Bayesian pose estimation approaches
3-1-2: Ensemble models combining multiple pose estimation techniques
3-1-3: Probabilistic graphical models that can handle uncertainty
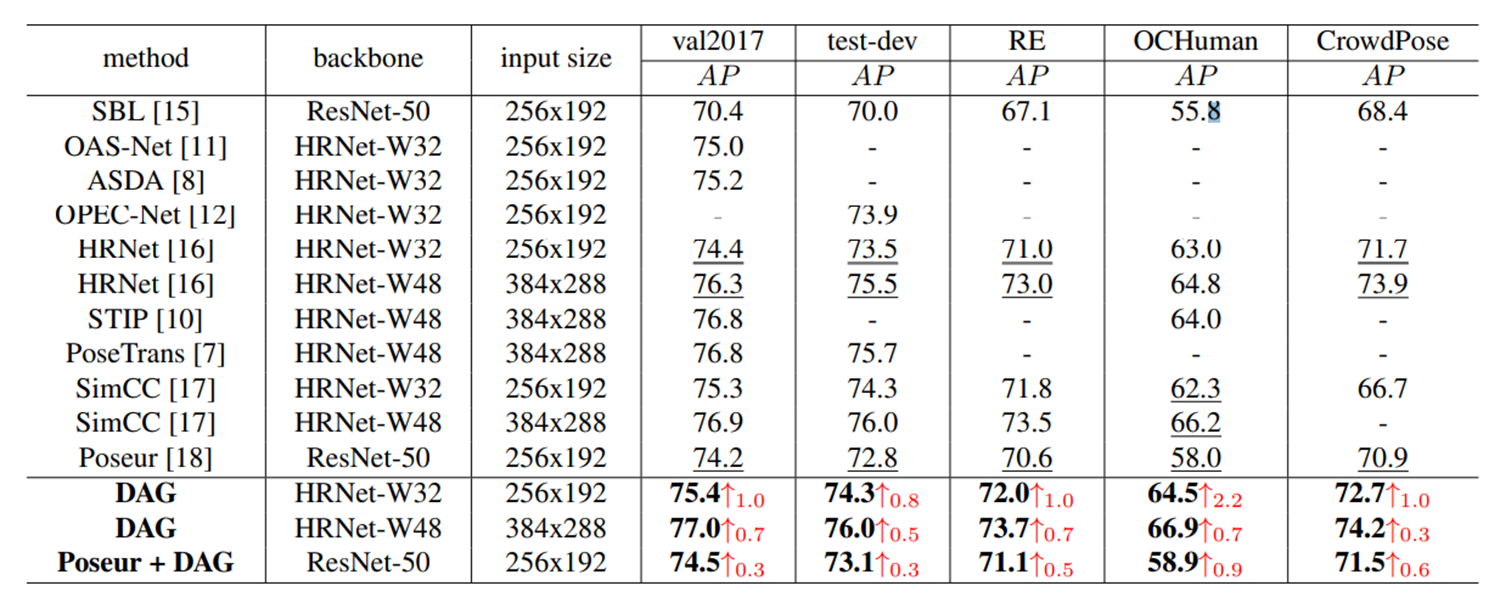
A comprehensive framework for occluded human pose estimation
paper : Xu, Linhao, et al. "A comprehensive framework for occluded human pose estimation." ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024.
1. Data Augmentation
2. feature map + GAP등을 통한 channel feature map 사용
3. 인접 관절 관계 + 멀리 떨어진 관절 관계 학습
[1-1-1] : Mask Joints, Instance Paste로 데이터 증강
[2-1-2] : ADAM, GAP를 통한 Channel 중요도 및 픽셀 중요도 학습
[2-3-1] : ADAM, FGMP-GCN feature extraction, adaptive feature learning
[3-3-1] : FGMP-GCN으로 인접 및 멀리 떨어진 관절 간의 관계 학습

(1) Data Augmentation
Mask Joints : image에서 keypoints를 의도적으로 가림
Instance Paste : 다른 인물의 신체 일부분을 합성
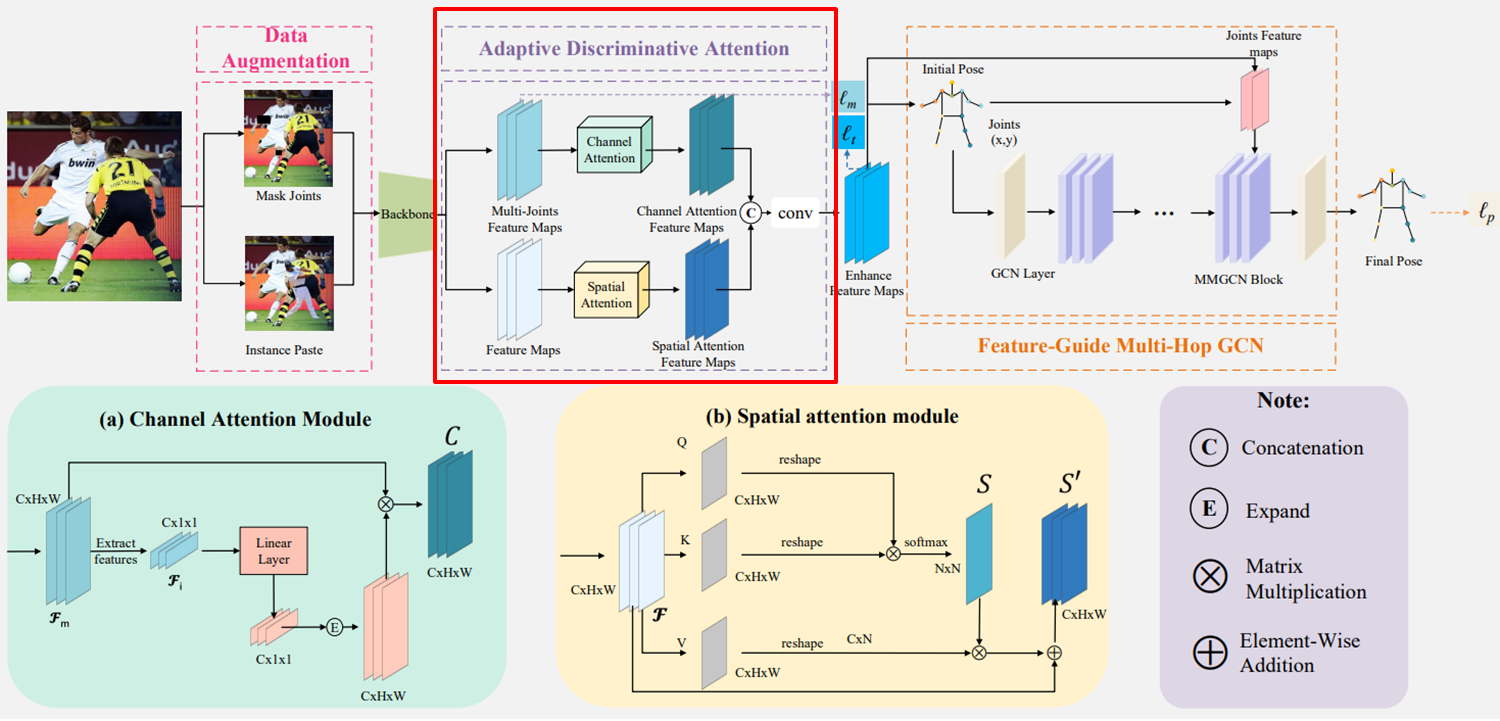
(2) Attension : Adaptive Discriminative Attention Module (ADAM)
feature map -> 각 관절 별 feature map으로 분리 -> Channel Attention 어떤 feature Channel(Type) 중요? lt
feature map -> Spatial Attention feature pixel 중요? lm
Enhance Feature Map : 중요한 feature type이 어느 위치에 있는가
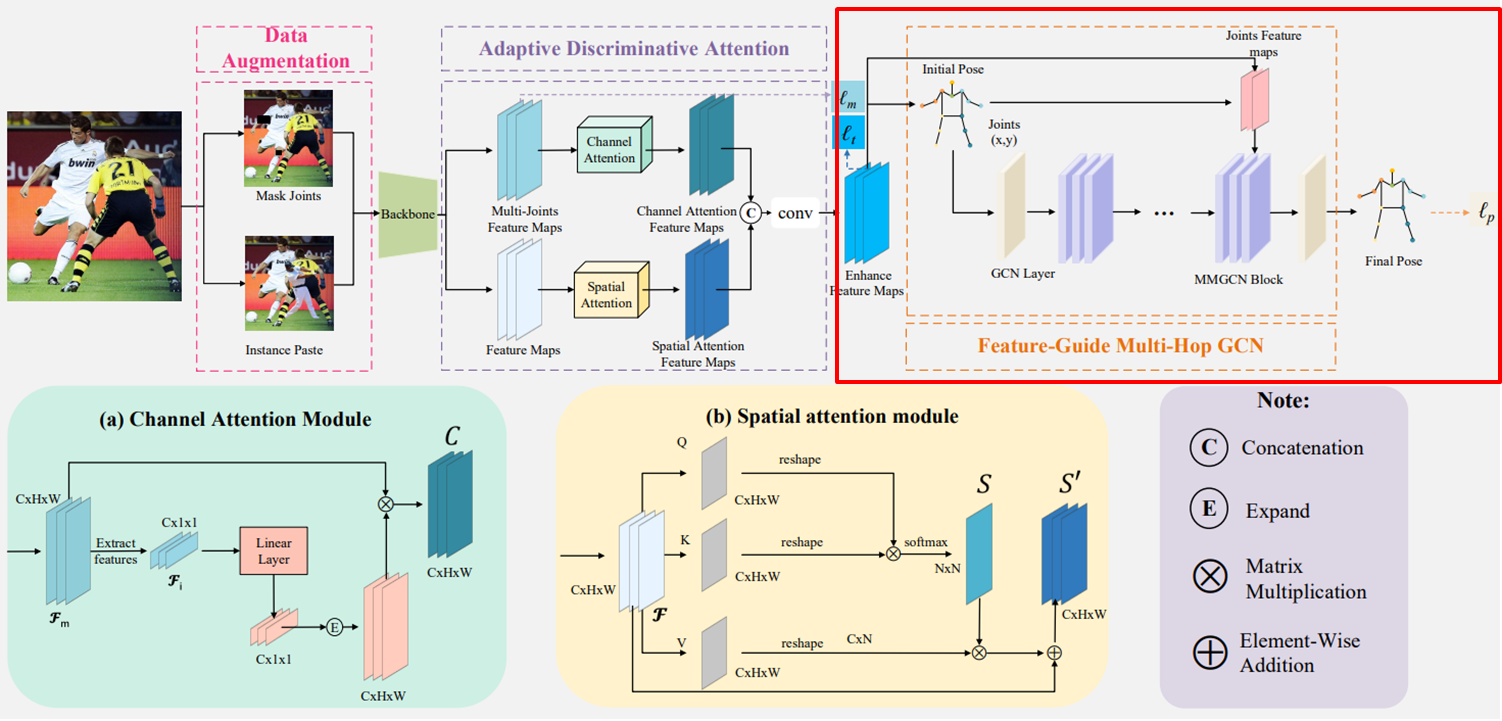
(3) FGMP-GCN
Init Pose : G = (V,E) V: keypoints, E : 연결된 node (관절 연결, prior knowledge)
GCN Layer : 인접 node, 관절 관계 학습
MMGCN Block : 떨어진 node, 관절 간의 관계 학습
prior knowledge를 통해 occulusion keypoints 보완
Poseur: Direct Human Pose Regression with Transformers
paper : Mao, Weian, et al. "Poseur: Direct human pose regression with transformers." European conference on computer vision. Cham: Springer Nature Switzerland, 2022.
1. Transformer기반 Direct Regression 방식으로 Pose Estimation
2. Backbone으로 Ref Keypoints 만든 후, noisy+Ref Keypoints 만들고,
noisy+ref keypoints와 ref keypoints로 각각 self-attention,
해당 결과로 backbone feature map과 cross-attention해서 keypoints출력
[1-1-1] : ref+noisy keypoints생성하여 학습
[2-1-3] : Tranformer기반 self,cross attention
[2-3-1] : self,cross attention으로 adaptive feature learning
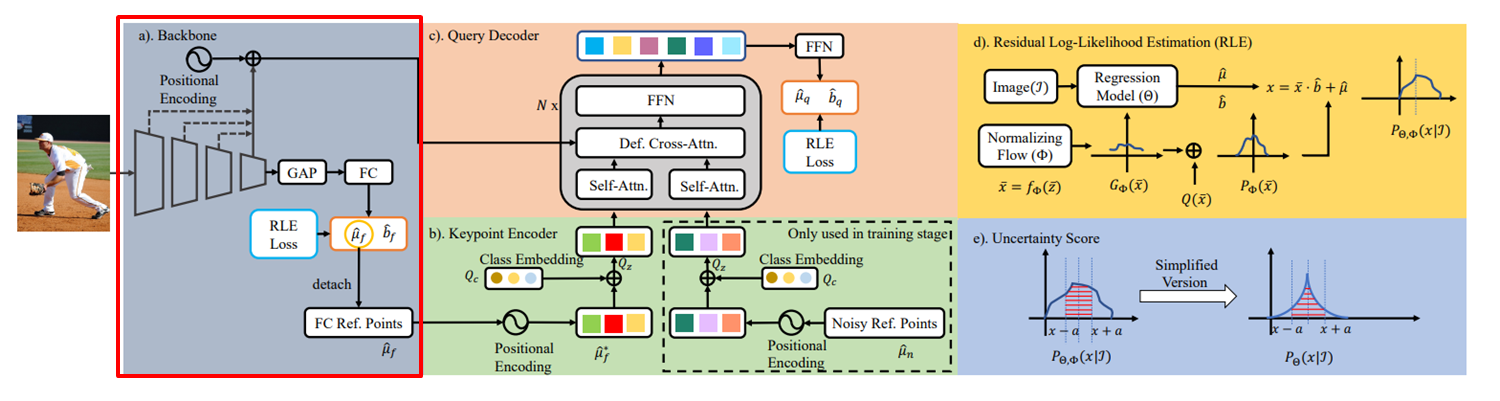
(1) Backbone
Backbone -> GAP로 feature vector로 축소(채널 축소) -> FC Layer를 통해 초기 reference points 생성
Positional Encoding : 좌표-위치 임베딩 (feature기반 위치정보 임베딩)

(2) Keypoint Encoder
관절-위치 임베딩 -> class Embedding : 관절별 class를 Embedding Vector 변환 (추정 관절 임베딩)
Ref. Points에 Noise 추가 (Augmentation) -> Class Embedding (추정+noise 관절 임베딩)
Keypoints별 Feature Vector Return
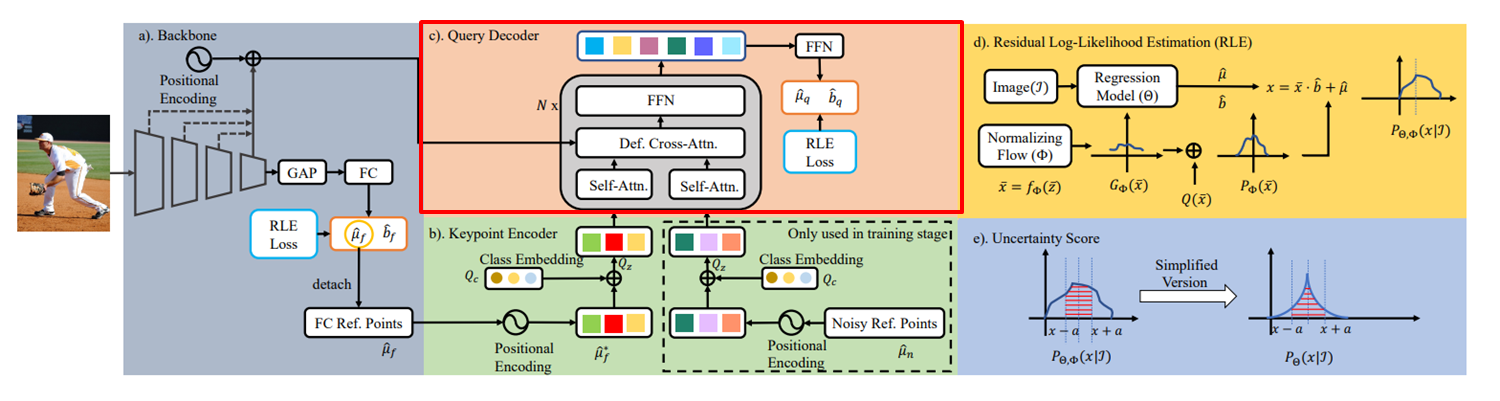
(3) Query Decoder
Noisy 추가 및 원 Keypoints를 Self Attention으로 각각 상호관계 추출
Cross Attention으로 feature-위치, 추정 keypoints, 추정+noisy keypoints 상호관계 추출
Query : Ref Keypoints, Key : noisy keypoints, value : feature-positional encoding
FFN : feature vector, 관절좌표 추출
어떻게 첫 번째 Method에 두 번째 Method 적용?
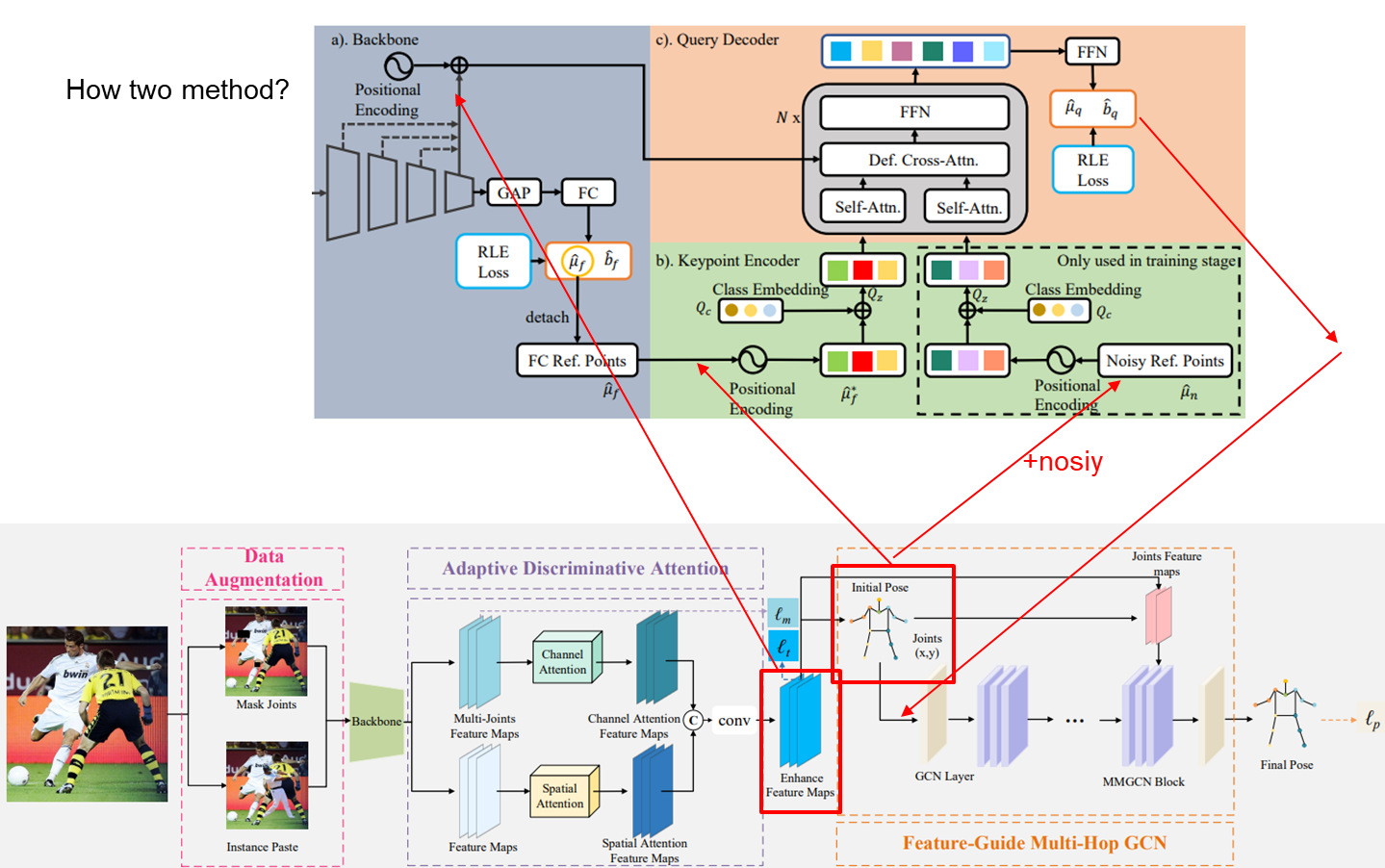
feature map기반으로 enhance feature maps 생성 후 positional encoding,
inital Pose를 Ref Keypoints로 사용,
FFN을 통과한 Keypoints로 init Pose 대체하여 GCN Layer, MMGCN Blcok을 통해 Final Pose 획득
Improving occluded human pose estimation via linked joints
paper : Ye, Suhang, et al. "Improving Occluded Human Pose Estimation Via Linked Joints." ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023.
1. 자세 추정시에도 관절 관계와 같이 학습 (Heatmap + skeleton map)
[1-1-1] : training시에도 사전 지식을 통해 관절을 더 잘 추정
[2-3-1] : Skeleton Map, Heatmap을 Element-wise Mul을 통해 학습
[3-3-1] : Skeleton Map을 통해 Context modeling
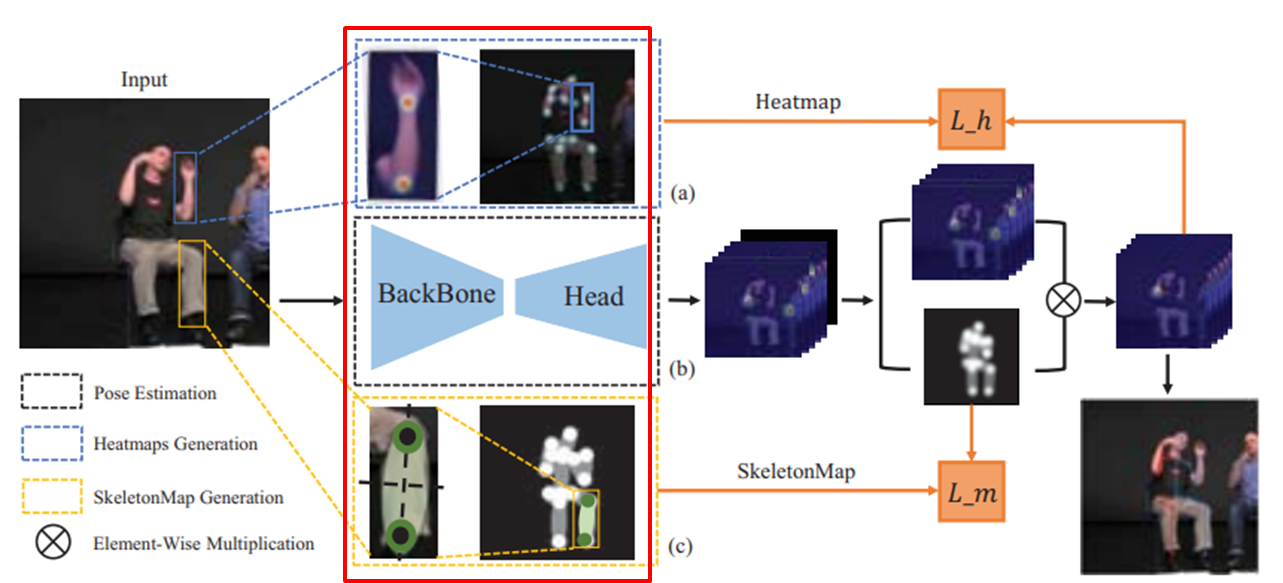
(b) backbone, head : feature 학습 및 feature map 추출, 자세 추정 결과 생성
(a) Heatmap generation : (b)기반으로 가우시안 분포를 따르는 heatmap 추출
(c) SkeletonMap
1. 관절간의 연결을 나타내는 skeletonMap 생성 (사전지식)
2. 확률분포 : 특정 위치값 원 1.0, 타원 0.5, 그외 0으로 설정 (이로써 관절간의 관계,위치 정보 표현)
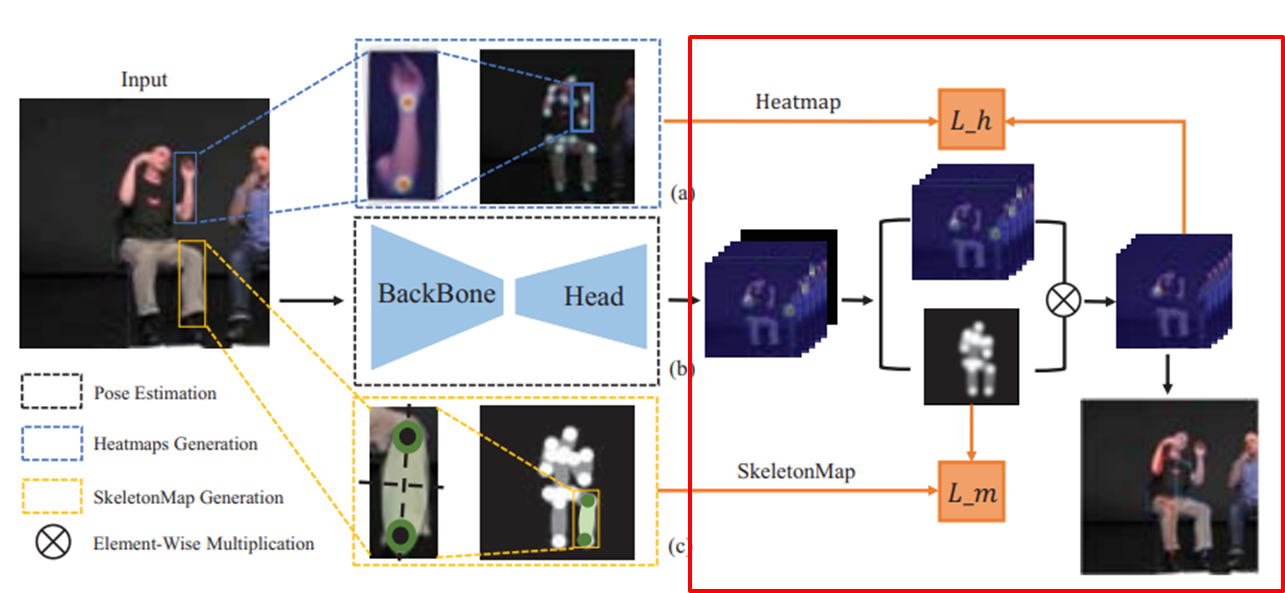
element wise Mul : (Keypoints heatmap (2d 확률), SkeletonMap) 최종 결과를 내고, loss 계산 및 학습
Occlusion-aware siamese network for human pose estimation
paper : Zhou, Lu, et al. "Occlusion-aware siamese network for human pose estimation." Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16. Springer International Publishing, 2020.
1. Feature Erasing, Reconstruction
2. Siamese network, optimal transport
[1-1-1] : image에 의도적으로 occlusion 만들고 해당 image도 사용
[1-1-2] : masking을 한 feature map 학습
[2-1-1] : occlusion image, original image multi-branch
[2-1-2] : attention, occlusion map 기반으로 feature train

1. input : occlusion image, non-occlusion image
2. backbone : F_o, F_j feature map 추출 (F_o : occlusion area feature map, F_j : joint feature map)

3. attention Module
occlusion feature map은 별도의 occlusion prediction head를 통해 occlusion map(H_o)추출
따라서 H_o는 가려진 정도를 0~1 값으로 변환
joint feature map을 통해 joint prediction head를 통해 H_j(관절 heatmap) 추출
F_j : Query, H_o : key, F_o : value 설정하여 F_c 출력
가려진 occlusion이 0이니까, 가려진 영역을 weight가 적게끔 되어 영향을 줄여서 F_c
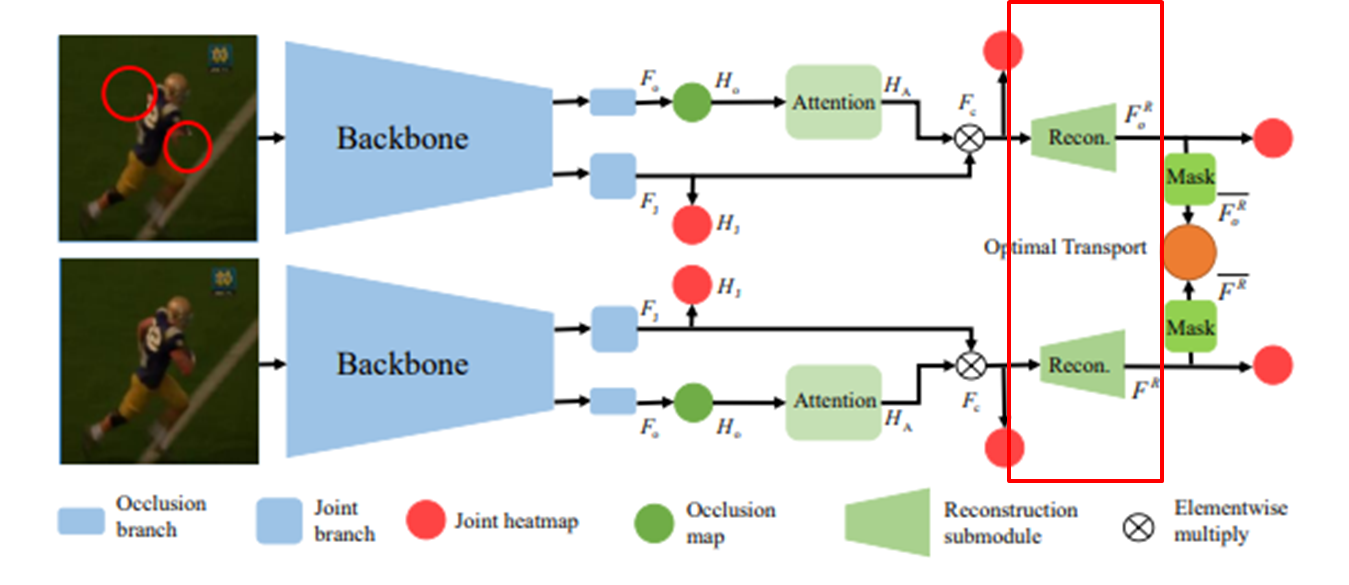
4. Recontruction Submodule
H_o (olccusion map), F_c(weight feature map)을 input
element-wise Mul해서 F_masked (occlusion area 0으로 되는)
F_masked를 통해 occlusion area는 근처 feature로 추정
F_c와 F_masked skip coneecdtion을 통해 가려지지 않는 영역을 유지하면서 (F_o)^R
즉, occlusion을 주변 feature 기반으로 복원

5. Optimal Transport
Mask 기반으로 feature map에서 occlusion area에 대해서만 수행
(F_o)^R : occlusion 복원된 keypoints feature map
(F_o) : occlusion 하지않은 image 기반으로 추출된 feature map
위의 두 feature map이 비슷해지도록 학습

Occlusion-robust objecat pose estimation with holistic representation
paper : Chen, Bo, Tat-Jun Chin, and Marius Klimavicius. "Occlusion-robust object pose estimation with holistic representation." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2022.
1.Occlude-and-blackout
2.Resolution-based multi branch
[1-1-1] : occlude-and-blackout 방식으로 augmentation
[1-1-2] : blackout
[1-1-3] : train dataset에 occlusion pattern 도입
[2-1-1] : 해상도 수준을 3가지로 나누어 multi-branch keypoint 추출
[3-1-3] : heatmap을 heatmap score에서 가우시안 분포에 따른 확률 분포로 표현

1. Input
Original input batch : original image
Occlude-and-blackout : original image의 일부 patch를 가리거나 제거 (augmentation)

2. ROI 추출 및 Feature map 생성, 이때, ROI는 original 기반으로 추출하여 occlude-and-blackout에 공유
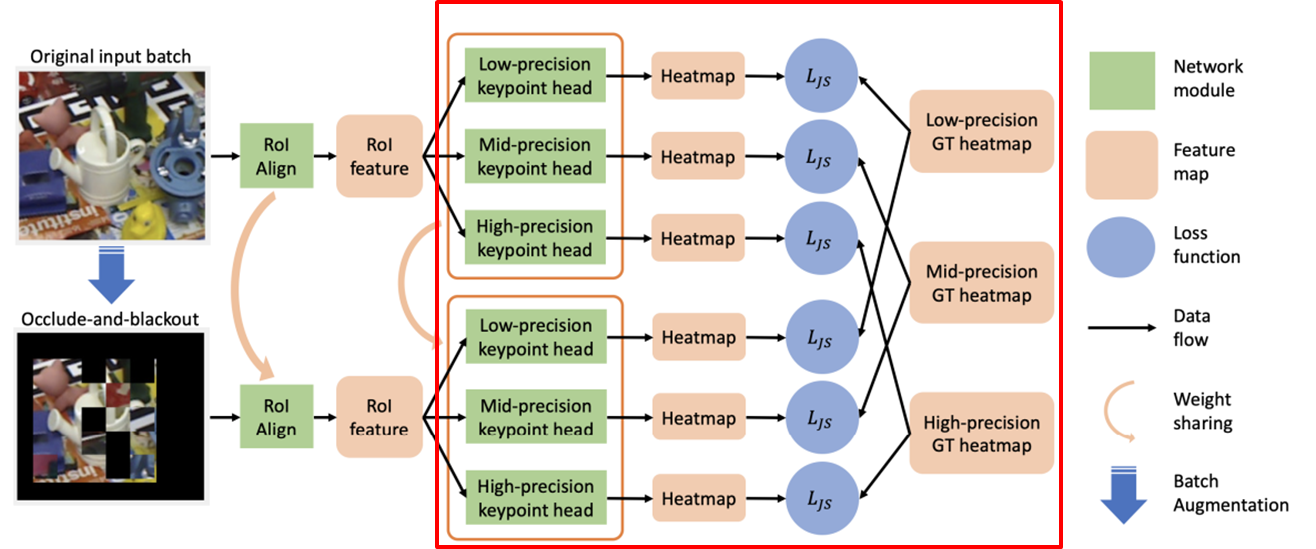
3. Resolution-based multi-branch
Low-, mid-, high- 로 나누고, ROI feature 기반 feature map에서
kernel size를 다르게 하여 결과적으로 해상도 수준이 다른 heat map 추출
(low- : 넓은 범위의 heatmap, high- : 정밀한 heatmap ...)
해당 heatmap score기반으로 softmax 등을 통과하여 heatmap 확률로 변환
loss function으로 GT와 비교하면서 학습
이때, original과 occlusion image들은 weight sharing을 통해 모두를 만족하는 weight train

'Study > computer vision' 카테고리의 다른 글
| DETR : End-to-End Object Detection with Transformers (0) | 2024.12.10 |
|---|---|
| [ResNet] Skip connection 제대로 이해 (1) | 2024.12.07 |
| [VGGNet] Very Deep Convolutional Networks for Large-Scale Image Recognition (0) | 2024.08.12 |
| [AlexNet] ImageNet Classification with Deep ConvolutionalNeural Networks (0) | 2024.08.09 |
| [LeNet-5] GradientBased Learning Applied to DocumentRecognition (0) | 2024.08.09 |