

1차 마무리 파일 구조는 다음과 같습니다. accuracy/*은 성능테스트 관련 데이터 및 코드이며,
config/*는 github에 올리지 못하는 중요정보 (s3 private key 등등), request_test/*는 locust를 활용한 다중동시접속 request test, routers/*는 각각 하나의 router들로써 api, routers/utils.py는 모든 router들에서 공통으로 사용하는 라이브러리 목록,
test_js/*는 js와 python mediapipe lib 성능비교
실험 환경
OS : Windows
CPU : i7-8750H @ 2.20GHz (12 CPUs)
GPU : NVIDIA GeForce GTX 1060
RAM : 16GB
1차. mediapipe model complexity별 processing time


[
{
"video_name": "modelTest_\uad50\uc218\ub2d8\uc601\uc0c1.mp4",
"video_duration": 5.5,
"download": 0.68057,
"model_performance": {
"Model0": 103.99326,
"Model1": 125.631,
"Model2": 396.87615
},
"detection_frame": {
"video": 165,
"Model0": 165,
"Model1": 165,
"Model2": 165
}
},
{
"video_name": "modelTest_\uc11c\uc9c0\uc6d0\ud504\ub85c1.mp4",
"video_duration": 3.0,
"download": 0.43441,
"model_performance": {
"Model0": 100.35946,
"Model1": 136.40392,
"Model2": 491.17194
},
"detection_frame": {
"video": 90,
"Model0": 90,
"Model1": 90,
"Model2": 90
}
},동작수행 router에서 다음과 같은 형식의 json을 생성하여 테스트 진행
2. model accuracy : 우리 서비스의 데이터와 model 비교, 주로 사용되는 address~finish까지의 데이터만 비교

(6개의 영상에 대한 평균)
우리 서비스의 데이터와 model 비교, 주로 사용되는 address~finish까지의 데이터만 비교,

3. golf step accuracy
: golfDB라는 논문 기반으로 GT데이터셋 다운로드 후 step을 얼마나 잘 잡는지 정확도 검출
해당 아카이브 링크
https://arxiv.org/abs/1903.06528
GolfDB: A Video Database for Golf Swing Sequencing
The golf swing is a complex movement requiring considerable full-body coordination to execute proficiently. As such, it is the subject of frequent scrutiny and extensive biomechanical analyses. In this paper, we introduce the notion of golf swing sequencin
arxiv.org

golf DB gt csv와 video를 통해 1300개의 영상 중 1차적으로 500개의 영상(1~500)만 남김
2차적으로 slow video 제거, 측면영상이 아닌경우 제거 (90개 test)
events항목과 비교하여 golf step이 GT와 얼마나 일치하는가를 테스트
비교할 데이터 준비
gpt를 통해 request url, handType formmating json 생성, locust를 통해 90개의 영상을 request
golf step을 detection하는 코드만 남긴 router로 진행
90개의 영상에 대해 json에 video name, step 저장 각 video의 step frame image 저장

(input video 160x160) PCE의 경우, step이 오름차순이 아닌경우 정확하게 판별안한것으로 계산
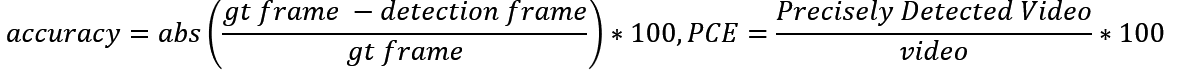


우리의 시스템이 golfDB에서 제안하는 방법보다 평균적으로 8step에 대해 더 잘 잡히는 것으로 확인,
추가적으로 address와 finish같은 경우는 비교 불가능할 정도로 우수한 성능을 보임
4. joint data accuracy : 각 관절별로 GT(Ground Truth) 데이터 대비 성능 확인
GT 데이터의 경우 golfDB에서는 제공하지않아, AI Hub를 통해 points 좌표 데이터셋 다운로드
https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&dataSetSn=65


Association/female/swing_01/특정 video만 존재 따라서 해당 json이 존재하는 video들만 추가로 다운로드

json에서 005부분은 points에 대한 좌표가 있으며
06은 bbox, 003은 polygon등 각각 학습하는 데이터가 다른것으로 확인
우리는 points가 필요하므로 005의 폴더에 있는 영상 및 json만 사용

“categories””keypoints”로 관절 순서, “class==person”인 필드에서 “points”를 통해 관절좌표를 가져올 수 있음
현재, 우리 서비스에서 cvPoselandmark를 json return하기에 cropping하기전 data를 이와비교,
class는 ball, club, person 3가지의 polygon과 person 1가지의 points로 구성 points는 (x,y,신뢰도)로 구성되있으므로len(points)=len(keypoints)*3

mediapipe에서 추정하는 관절과 동일한 항목에 대해서 정확도 검출,
hip ankle등은 데이터를 중점 좌표등을 사용하여 정확도 검출할 수 있으나, 중요성이 낮으므로 제외


결론적으로, golfDB에서 제안하는 딥러닝모델보다 우수한 성능으로 step을 잡고 있으며,
joint 별 data accuracy도 굉장히 높은것으로 확인. complexity가 다른 mediapipe model들을 섞고,
데이터 전후처리를 통해 우수한 성능을 뽑았음. 하지만 이렇게 됨으로써 실행시간이 증가하는 현상 발생
실행시간을 감소하는 방향 탐색

다음의 workflow를 따른다면 server에서 실행되는 시간을 front(user)에서 덜어줄 수 있어
실행시간 측면에서 큰 기대를 보일 수 있을 것으로 판단, 해당으로 수정 계획 중
추가로 실행시간을 줄이기 위해 load balancer or ECS 등을 고려 중.
AWS EC2 CPU별 스트레스 테스트 이미지 첨부는 아래
ec2 (Linux기준)
c5.large : 2 vCPU, 4 GiB, $0.096 per hour
c5.xlarge : 4 vCPU, 8 GiB, $0.192 per hour
c5.2xlarge : 8 vCPU, 16 GiB, $0.384 per hour
c5.4xlarge : 16 vCPU, 32 GiB, $0.768per hour
lambda
9초걸리는 영상의 경우 $0.01875
c5.large 기준 1시간에 5번 이하
c5.xlarge 기준 1시간에 10번 이하
c5.2xlarge 기준 1시간에 20번 이하
c5.4xlarge 기준 1시간에 40번 이하의 request가 있을 경우 lambda가 유리하다.




1차 마무리 기능에 대한 자료를 생성했으나 첨부하면 안될 것 같아서...(알고리즘...) 맛보기만
8step 판별 중 일부

elbow 예측 중 일부

'Project > golf_AI_Serivce' 카테고리의 다른 글
| 석사 학위 논문 리뷰 (5) | 2024.11.28 |
|---|---|
| [golf_AI_Service] library 정리 (0) | 2024.09.02 |
| [golf_AI_Service] 1차 마무리 (0) | 2024.04.01 |
| [golf_AI_Service] 기능 (2) | 2023.11.26 |
| [golf_AI_Service][lambda] 조금 더 자세한 내용 (0) | 2023.08.10 |